|
When testing a new chip design there is a lot of work that goes into characterizing the design to determine if it meets specifications. One such type of testing is characterizing an ADC. DC Evaluation, Gain and Offset The purpose of an ADC (Analog to Digital Converter) is to take a continuous time analog signal and convert it into a discrete time digital signal. We talk about ADCs in terms of bits. So you might have a 4 bit ADC which means that the full scale analog value that can be an input to the ADC is divided by 2^4. 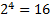
And (let’s say) 1.0 volts is your full scale input. Then, 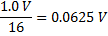
So, each digital step after the ADC conversion represents 0.0625 volts. Now this is an ideal behavior, in reality no ADC will work perfectly like this. The Gain of an ADC can be defined as follows: 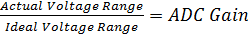
The offset of an ADC is defined as voltage difference between corresponding inputs and outputs. This may not be the same for all inputs, but an average of all the offsets at each, or several inputs would serve as a good general offset number. ADCs are statistical in nature One unavoidable problem with an ADC is it’s inherent statistical nature. If you think about how an ADC works, multiple analog voltages will result in the same digital voltage output. The extent this is seen is dependent on the resolution of the ADC. As shown above in the 4 bit ADC calculation, each digital step corresponds to a finite voltage value. If the input voltage to an ADC happens to fall right on the edge of transitioning from one level to the next then some of the time you will get the smaller code some of the time the larger code. That's what I mean by statistical, given enough data you can determine what percentage of the time the ADC will output what code. Ideal and Non-Ideal ADC In an ideal ADC each code would have a uniform width and center point. Figure 1 shows an ideal ADC curve of a 4 bit ADC. In reality, an ADC is non-ideal, which can be observed in the following ways: Codes are non-uniform Figure 2 shows an example of a code that is longer than the others. Code transitions are not clean Figure 3 shows and example of code transition that is not clean. That is when the ADC is tested as it approaches the code transition point the code might bounce back and forth a few times before transitioning. 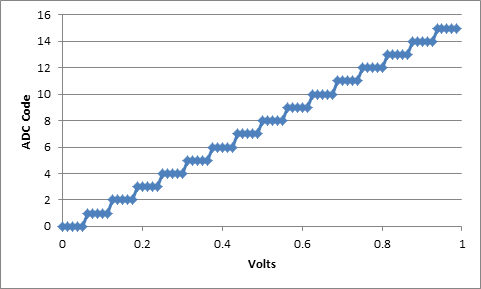
Figure 1. Ideal ADC Transfer Curve
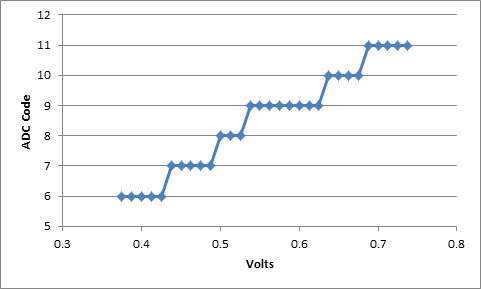
Figure 2. Code 8 and 9 are not uniform
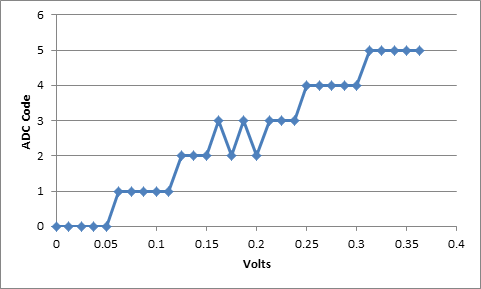
Figure 3. Example of an indefinite transition point from code 2 to 3
ADC Transfer Curve Figure 1 is an example of an ADC transfer curve, plotting input voltage vs. ADC code. Plotting the transfer curve is how to characterize the ADC. There are a lot of different methods to characterize the ADC and ways to generate the transfer curve. I'll describe the linear ramp method I have experience using. Linear Ramp ADC Characterization Here is the basic setup to characterize and ADC with a linear ramp. 1. Set a function generator to create a slow ramping voltage starting at the minimum voltage input and ramping to the maximum voltage input of the ADC. The ramp should be slow enough that multiple input analog voltages will result in the same output code. I'm talking at least 10 here. This will allow you to see the transition points clearly. 2. Setup the ADC to read codes for the entire time that the linear ramp input is on. 3. Save the ADC output somehow, this is probably read out of some memory in the system with a script like in LabVIEW or Python (some programming environment) 4. Plot the transfer curve. You may want to do a few trials or try a few instances of the ADC for repeatability and reproducibility study. Characterization Calculations Once you have gathered your ADC data, there are a few calculations to make that will gauge the performance. 1. Find the edges In the ideal ADC transfer curve it is obvious where the code edges (transition points) are, but in a real ADC it is not as obvious. What you have to do is create a histogram of the ADC output codes. All this does is group the like codes back together at the transition points and create a clean transition point. So, if you look at Figure 3, it is not clear where the transition from code 2 to 3 is. Creating a histogram basically moves all the output codes of 2 together on the left and moves all the output codes of 3 together on the right. This creates a clean transition edge. While we can’t really be sure this is the real edge of the ADC this is the best we can do to move forward with our analysis. 2. Generate the Ideal ADC Transfer Curve This is just a matter of creating an ideal curve like shown in Figure 1. 3. Calculate the Monotonicity Calculating the monotonicity is a measure to verify that each output code will be larger than the previous one when an increasing signal is being applied as input. This is probably not that likely to be a problem when the input signal is slowly increasing (or decreasing) ramp signal. Here is the equation for monotonicity: 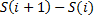
For a 16 bit ADC i is the steps 0 to 15 and S(i) is the voltage equivalent. And, S(i+1) is just the next higher point. 4. Calculate and plot the DNL – Differential Nonlinearity DNL is a measurement to determine how uniform the output code step sizes are for a linear ramp input signal. 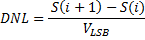
For the 16 bit ADC 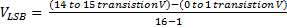
5. Calculate and plot the INL – Integral Nonlinearity INL is a measure the ideal ADC transfer curve versus the actual transfer curve. 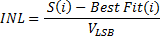
What is equation will do is when you plot this line it will exaggerate the places where this curve deviates from the ideal line and you will get a good snap-shot view of the linearity.
Summary The important aspects to characterizing an ADC are to determine the gain, offset, DNL and INL. The steps to characterizing an ADC are to: Determine your input voltage range, setup your experiment, gather the data and analyze the data.
2 Comments
I have changed roles again. I'm back working as a test engineer.
What happened was, the electronics packaging department and the test engineering department fell under the same larger department. I kept getting more involved in test engineering projects and less in packaging projects. So, with my management we decided it would make more sense if I just moved officially to the test engineering department. I'm very happy to be back in test engineering and feel very good about the work I have coming up. My first new responsibility will be working on a wireless test system, which is something I have not had a chance to do. So, I'm very excited. Hypothesis testing is an interesting subject. I can’t say that as a test engineer I use hypothesis testing on a regular basis, but it’s a useful thing to know a little bit about. The basic concept is that you have an idea of something being true (a hypothesis) and hypothesis testing coupled with a statistical method to analyze data is used in order to determine if your idea is true. For example, let’s say that under ideal conditions a voltage measurement will always measure 5 volts. Now, I want to know if I make the same measurement in a high humidity environment, will that significantly affect the measurement average. This becomes the null hypothesis and the alternate hypothesis. The null hypothesis is denoted by Ho and in this example is that the voltage measurement in high humidity is equal to 5 volts. The alternate hypothesis is denoted by H1 and is that the measurement under high humidity is not equal to 5 volts. It’s always confusing to me what is supposed to be the null hypothesis. The rule is that the null hypothesis is always assumed to be true. This is confusing because it depends on how you phase the null hypothesis, but here we are interested in a factor (humidity) altering the desired state of measuring 5 volts accurately. It doesn’t really matter what we think is going on. We might think that the humidity does have an effect, but until we can prove it (prove the alternate hypothesis is true) we assume the null hypothesis is true and everything is normal – 5 volts is measured accurately. I kind of think of it as the least interesting or default condition is always the null hypothesis. Example At this point it is easier to just turn the voltage measurement discussion above into an example. I used Labview to generate 100 random numbers to serve as the 5 volt measurements. I intentionally made the data skew slightly above 5 volts. I’m going to use the 1 sample T test in Minitab statistical software to perform the hypothesis testing. I should say that this is kind of trivial example, the real power is when you start using analysis of variance (ANOVA) to look at how multiple factors at multiple levels affect a process. The analysis was performed six times, each time reducing the number of samples that was used. Reducing the samples will illustrate how the decision to reject or fail to reject the null hypothesis becomes less certain. Figure 1 shows a partial screen shot of the data in Minitab. The columns are labeled with the number of samples in that column. 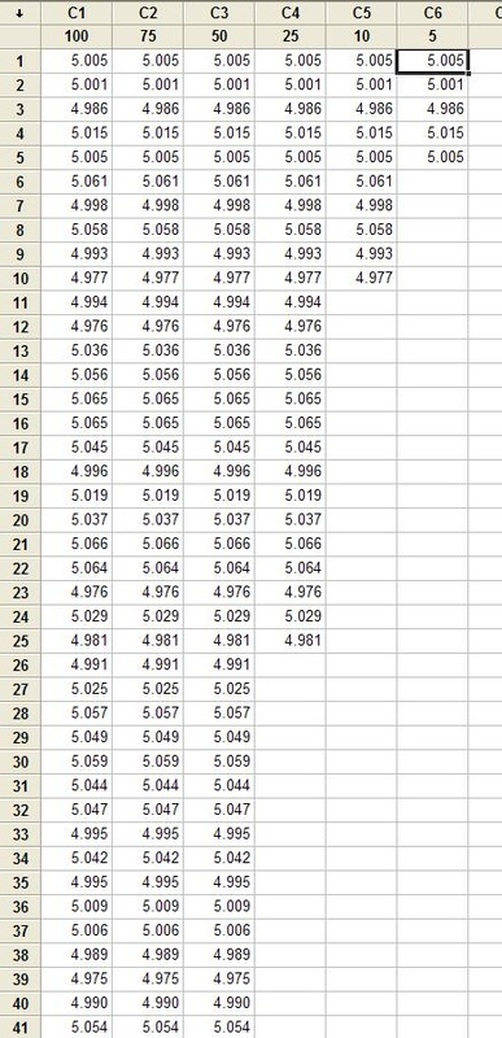 Figure 1. Partial screen shot of measurement data of different sample sizes Figure 2 shows the output of the T test from Minitab. 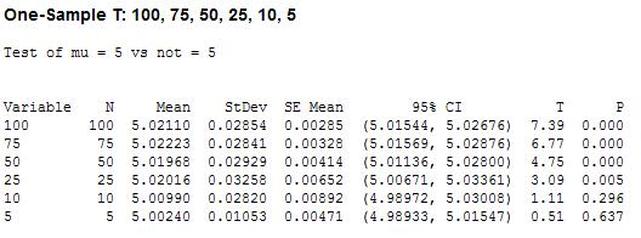 Figure 2. Results for 1 sample T test in Mintab of various sample sizes
In Figure 2 we can see that the column “N” is the number of samples. It shows that mean generally gets closer to 5 with fewer samples. The interesting result here is the P value in the last column. The results are not interpreted by the tool for us, but the rule is that since we are using a 95% confidence interval, any P value less than 0.05 would indicated that we should reject the null hypothesis. So, what’s all that mean? The P value is a probability value that tells us the probability that the null hypothesis is true. For N = 100, 75 and 50 it is saying that there is basically no possibility that the null hypothesis is true and we should reject the null hypothesis in favor of the alternate (and thus the humidity is having an effect). When N = 25 the P value is 0.005, which is still smaller than 0.05 and so we should still reject Ho. For N = 10 and 5 the sample size has gotten small enough that it’s now getting more likely that the mean is in fact 5 V, and we should fail to reject the null hypothesis. Figure 2 shows that we are using a default 95% confidence interval, that’s where the P value cut-off of 0.05 comes from (1 – 0.95 = 0.05). For N = 100, 75, 50 and 25 we are better than 95% confident that the mean is not 5V. You may be wondering why we would do all this. Why not just take a bunch of measurements and calculate the mean? That’s obviously important, but we can always argue that if we take way more measurements (samples) on top the current amount, then the mean will change. That’s why we use this tool, based on the number of samples, we can establish to with some level of confidence weather or not the mean is what we think it is. The results show that we get more and more confident as to the result as we add more samples. Hypothesis testing is also used by manufacturing and quality engineers where you have to sample a value from a process or a production line to try to figure out if the process is at the nominal value or drifting. Summary Hypothesis testing is a useful statistical concept for a test engineer to know and used by a lot of other technical people as well. This was a pretty simple explanation, but hopefully helpful. The steps in hypothesis testing are. 1. Determine your null hypothesis 2. Gather data 3. Assume the null hypothesis is true 4. Determine how much different you sampled values are different from your null hypothesis 5. Evaluate the P value P < 0.05 reject and P > 0.05 fail to reject. The mnemonic device is “If P is low, Ho must go” A statistical concept that comes up often for me as a test engineer is the process capability index. This is a statistical concept that comes from statistical process control and is used on a process that is in control. I don’t really do anything with process control or control charts, but the process capability index is still a useful tool when you are developing tests and need to quickly evaluating a measurement and the feasibility of test limits being applied to it. Cpk When applying test limits to a measurement a design engineer (or someone with more knowledge of the circuit in question) may have an idea of what those limits should be, or they may just be offering a suggestion, making an approximate estimate. In this case, it may be wise to establish a temporary limit to be evaluated when more measurement data is available. Once a good sampling of the measurement data is available the limits can be evaluated to determine if they are going to be capable or if the measurement population is going to be coming very close to the specification limit when the measurement is taken a higher volume in production. Using the process capability index gives a hard number to tell you if you are right up against the specification limit and are going to risk a big fall out if the process shifts. One such process capability index is the Cpk statistic. Here is the formula for Cpk.  The little hats just mean that these are estimates. Figure 1 shows a plot of 20 measurements of a 5 V power supply (I just made these numbers up for illustration) 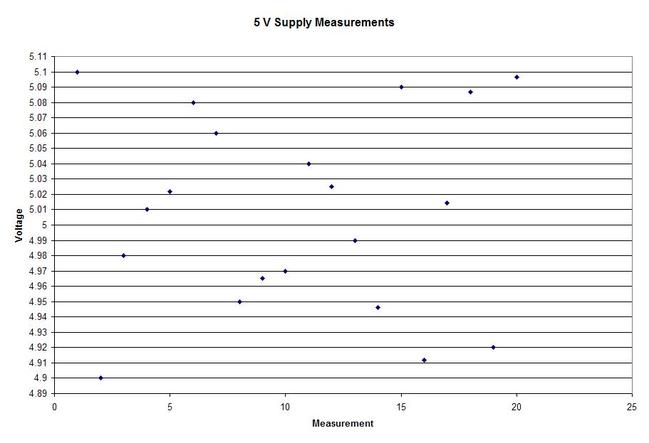 Figure 1. Measurement of a 5 V power supply repeated 20 times. Let’s say that we are measuring a 5 V power supply with an upper and lower specification limit (USL, LSL) set at 1%, 5.05 and 4.95 V. Figure 2 shows these limits marked on the plot. There is obviously some problem here as there are several failures. Calculating Cpk is not really necessary in this case but the result would be: 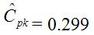 This is a bad result, any Cpk less than 1 is not good and ideally you want it to be over 2. 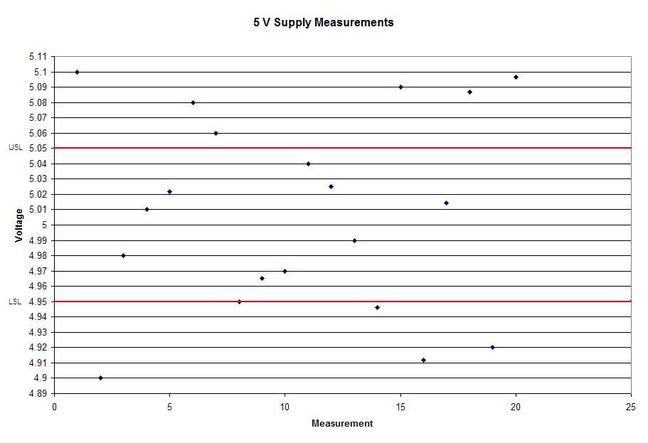 Figure 2. Measurement of 5 V power supply with 1% specification limits. Let’s try 10% limits of 4.5 and 5.5 V as shown in Figure 3. Now we get: 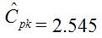 Cpk of 2.545 indicates that the limits are very good and the measurement population is not going to be close to either the low or high limit and is not close to having a lot of failures should the population shift. 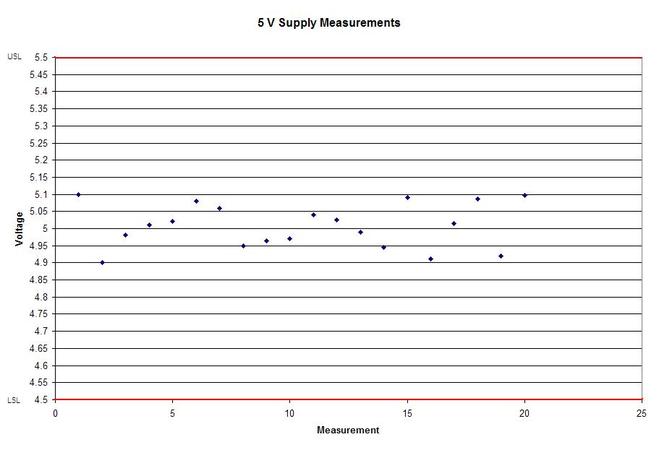 Figure 3. Measurement of 5 V power supply with 10% specification limits.
Now obviously Cpk is not the only factor in setting limits. You don’t just expand the limits if the Cpk is less than 2. The limits would ideally be calculated based on the component tolerances and using a monte carlo type analysis. However, the Cpk is useful in evaluating if a measurement is accurate and if it can be expected to have failures when under higher volume manufacturing. Summary The process capability index is a statistical concept taken from process control that is useful for test engineers to evaluate limits and measurement performance. Cpk is one method of calculating the process capability index. Cpk will help to evaluate how close a measurement population is to either the lower or upper limit. This is useful in predicting future test failures and determining if the measurement accuracy can or should be improved. A while back, actually quite a while back, I decided to start adding some test engineering related projects to this site. The first one I took on was developing a test executive from scratch in Labview. I realize that NI has the TestStand product that is an off-the-shelf test executive. I have not used TestStand in years simply because my company does not currently use it. I’m sure what I’ve developed is no match for TestStand, but there is room for developing your own test executive. Some reasons may be you don’t want to pay for TestStand (although it will cost you time and effort to develop your own). Perhaps TestStand is overkill or maybe it will not meet your needs. Basically, developing a simple test executive was a good test related project that would require fairly extensive user interface development. I’ve given my test executive a name, the DOT-TE or Dana On Test Test Executive. That seems a little more cute and clever than I like to be, but it gives me something to name the VIs. I’ve spent quite a while working on this as I have been working on it in my spare time. Like most engineers, I didn’t think it would take as long as it has. This project is still pretty far from being a stable test executive that could be used in a manufacturing environment. In fact I think it’s at about version 0.1. If you look at the specifications and code there are some features that I have not yet implemented, I could keep working on it before making this post but I just feel like it’s time to ship (so to speak). Prototype The way I decided to tackle this problem was to first create a prototype of the user interface with stubs of the main functions I wanted it to have. I saved the prototype that was created; it’s posted in Projects and Code page in the DOT-TE.zip file as “DOT-TE_Main_UI - Prototype.vi”. The point of the prototype was to get an idea of the look and feel of the user interface and help think of all the functions a test executive would need. The main user interface is based on the Producer Consumer design pattern that comes with Labview. Each button click or menu click puts a message into a queue (producer) and sends the message to execute some related code (consumer). Project Planning After I had the prototype the way I wanted it, I tried to write some specifications. I suppose writing specifications wasn’t all the necessary for a project the only involved one person, but I wanted to make this somewhat a true-to-life project. Here are the original specifications I wrote after I had the prototype. Looking at this, I’ve implemented less than half of this: Specifications log in with different privilege test modes sequence file reports print a report database access db limits db store results db sequence file looping subset testing display status and messages display tests p/f input test information PN SN MN Comment load test button run test button edit sequence edit limits directory storage control setup controls like printing display system messages App Database will hold: Test sequence Limits System Database will hold: Test results/reports Put error messages to the System Messages Obviously, the specifications were nothing elaborate. I just wanted to try to make myself think of all the features it should have. In addition to the specifications, I wrote a program flow to try to map out how the test executive would be used and how it should behave. This expands on the specifications and was a way for me to think and write some notes. I have not edited this from what I originally wrote. Test Starts Internal: - Initialize the menu system - Initialize System Messages - Initialize Test Status, Detailed Results and Test Reports to be blank. - Check for the application database External: - gray out Load Parts, Run Test, Abort Test - System Messages - “System Initialize…” - “System Idle.” Load Test External: - select a test from file dialog - populate the tabs - Test Status Tab - list tests - Detailed Results - list tests - list measurements - System Messages “Test Application X Loading…” “Test Application X Loaded Successfully” - enable Load Parts button - System Messages “System Idle” Internal: Load Test button has been pressed. Go to case “BUTTON – Load Test” Go to the default or current test application directory and display the directories available to load. Display the system message “Test Application X Loading…” Check for a valid test application database Check for a valid sequence file and limits file from the application database Read the limits file from the database and hold it in memory somehow. Read the sequence file from the database and hold in memory somehow. Make visible Test Status, Detailed Results and Test Reports listbox, table, whatever with the tests listed. Test Status - lists the tests - add a test loaded Boolean - add pass fail text and Boolean Detailed Results - list the tests - list all the results by reading from the limits file Load Parts External: - put cursor on the “site” field of Test Information - gray out “Complete” button - once “Complete” is pressed enable “Run Test” button - System Messages “Loading Parts…” “System Idle” Internal: - Put the Test Information into a global - When all required Test Information is entered, enable the Complete button - Enable Run Test button and turn on the Test Loaded Boolean when the Complete button is pressed. Run Test External: - update Test Status after each test with p/f - update Detailed Results after each test with measured values and p/f - update Test Reports tab with report when done - generate overall result on front - System Messages “Test Running…” “Running Test X” “Testing Complete” “Report upload to database: Success/Failure” “System Idle” - while running gray the Exit button Internal: - call each test vi according to the sequence file and execute - determine the result of each test - determine overall result - generate test report - check if printing Unload Test External: - clear Test Status tab - clear Detailed Results tab - System Messages “Unloading Test…” “System Idle” - gray - Load Parts - Run Test - Abort Test Internal: Abort External: - stop testing when current test ends - System Messages “Aborting Testing…” “System Idle” Internal: - read from sequence to determine next test Menus - disable menus while test is running. Other Functions (Options) Print Setup (default off) External: - print on completion - print on fail - print all results summary only - print failing results only Internal: Looping (default off) External: - stop on fail - number of times to loop - System Messages “Looping Enabled” Loop stats while looping Test Subset External: - display all tests for loaded test or display no test loaded - radio button for test to run - select all button Application Directory External: - browse to where you want to load test apps from Tools Test Sequence External: - set the names of the test to run (add, remove test) - set test execution dependencies - select the limits file to use with the test application - select the test application name Limits File Fields: App Number App Name Test name Test ID Limits Part Model Serial Units Database – DOT-TE (maybe just make this a folder where the test reports go in the first version) Holds: Test Reports Database – DOT-Test_App Holds: Table 1 – test sequence Table 2 – limits file Looking back, I didn’t do a lot of this, but I feel like it was worthwhile as part of the process. Operation The project was implemented in Labview 8.5 (I know, I’m several versions behind, but that’s what I have access to at the moment). If you go to the Project and Code page of the website and download the code, everything is included in the DOT-TE.zip file. Within the DOT-TE.zip file the project is controlled by the Labview project file DOT-TE.lvproj. The folder “DOT-TE” can go anywhere, I’ve been putting it right under C:\. The test executive code is in the folder DOT-TE Application. The test application is in the Apps folder. The test application is like the actual test code that would be written to test a DUT. The test application is run on the DOT test executive. The example test application I wrote called DOT-Test_App_00001 includes five test VIs that would test some commonly grouped functionality of the DUT. The five tests output constant values in place of real measurements. There is also some code in the five tests to hook into the test executive and make the measurements accessible to it. Opening DOT-TE_Main_UI.vi it executes automatically to start the UI. The idea of the interface is to follow the buttons on the left hand side, working your way down starting with “Load Test.” Figure 1 shows the UI with all buttons other than “Load Test” and “Exit” disabled. This is the default state. 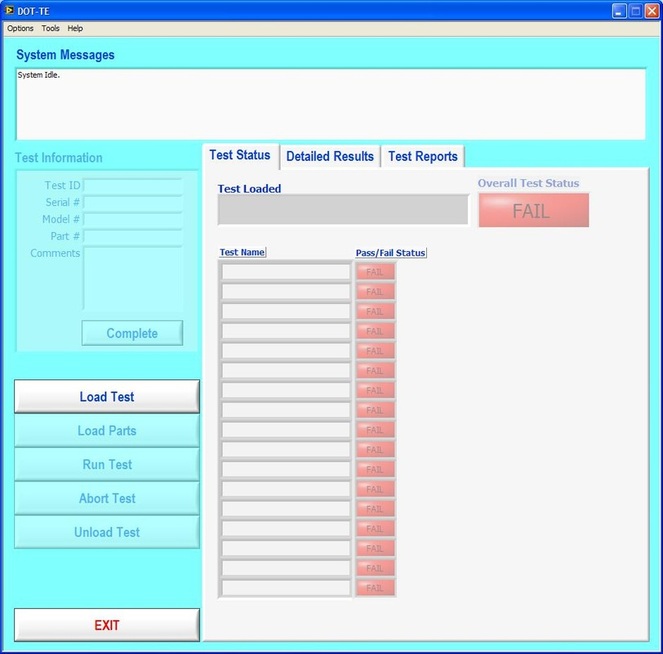 Figure 1. Default view DOT-TE user interface. At the Load Test file dialog select the test application file “Test_App_00001.txt” in Apps\DOT-Test_App_00001, this will load the test application. Figure 2 shows the “Test_App_00001.txt” file dialog. 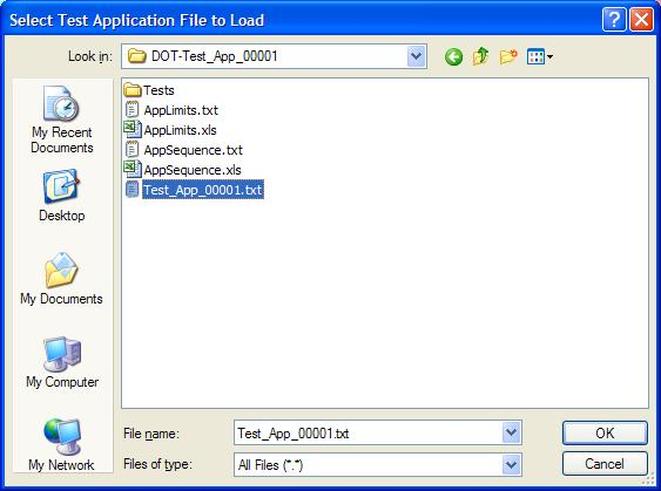 Figure 2. Selection of the application file when “Load Test” is pressed. Pressing “Load Parts” will make the Test ID field of the Test Information active. The test information is how you would identify an instance of the DUT you are testing. The test ID will accept any free text as will the serial number fields. The idea of the Test ID is you would have some system of how to identify a particular test run and enter this there. The serial number would be the serial number of the specific DUT you are testing. Entering the Model # and Part # fields will popup dialog boxes allowing the user to select from the model and part numbers that are listed in the limits file. The purpose of the model and part numbers are just more information to identify your DUT. This is useful, for example, because different model numbers could indicate slightly different DUT configurations. So, two model numbers may have all the same measurements, but different limits need to be applied to those same measurements. What’s nice is there can be a small change to the DUT and the test application and test executive are able to handle it without creating an entirely new test application. Digressing from the UI for a minute, Figure 3 shows the limits file I have mentioned a few times above. 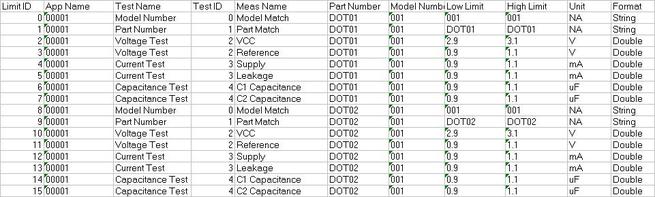 Figure 3. AppLimits.xls limits file The limits file is edited in Excel and saved as a tab delimited text file for the test executive to access. The limits file in Figure 3 has several fields, and five fictional tests. You can see that each line of the limits file is uniquely identified with the “Limit ID” column. This limits file has two instances of the same tests, one for part number DOT01 and another for part number DOT02. I’m not really using the model number as it’s only there to make the possible DUT configurations more flexible. Each test and measurement has a unique name. All the limits are the same for my two part numbers, with the exception of the Model Number test. The app name 00001 comes from the test application name Test_App_00001. The intention is all test application names would take the form Test_App_XXXXX. I guess it’s not that descriptive, maybe that should change. Getting back to the test executive UI and entering the test information. When you tab to the Model # and Part # fields you will see the two dialog boxes in Figure 4 respectively. 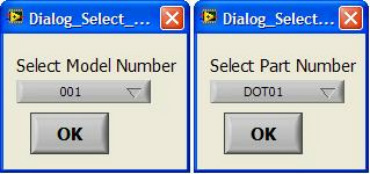 Figure 4. Select Model Number and Select Part Number dialog boxes. Again, the pull down in each of these dialog boxes is populated from the limits file model number and part number columns. Finally, pressing the “Complete” button in the test information section will fill in the information in the “Test Status” and “Detailed Results” tabs of the interface and enable the “Run Test” button. See Figure 5. 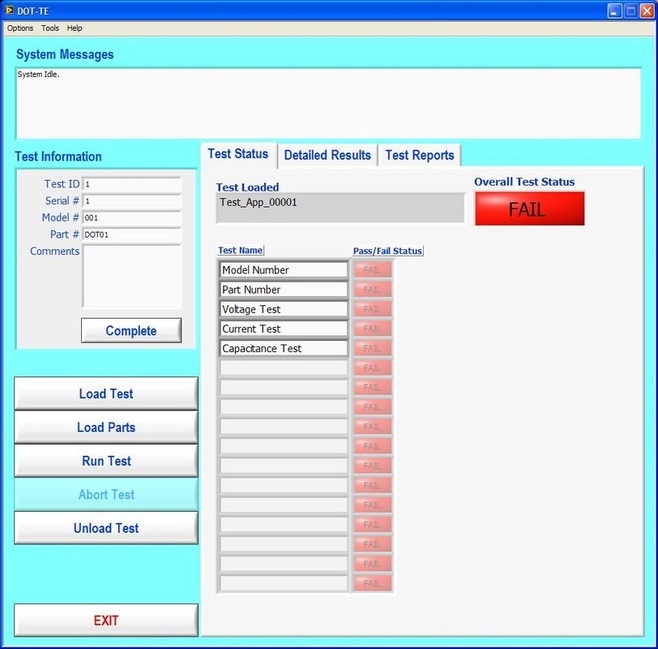 Figure 5. DOT-TE UI with parts loaded and Run Test button enabled. Actually running the test is somewhat anti-climatic because the results are just hard coded for this example test application. Figure 6 shows the directory that holds the test VIs executed when the test is run through the test executive. Again, there a no real measurements happening, but the idea is these VIs would be where you perform the actual measurements on the DUT. You can see in Figure 6 the naming convention I have chosen for the tests. TEST-(test name)-(app number).vi. 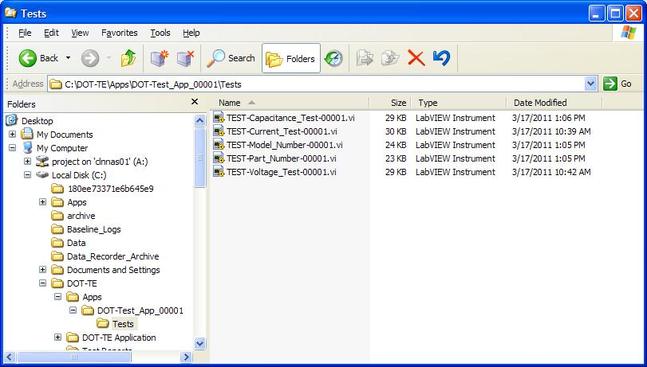 Figure 6. Test application test directory. As a result of running the all the tests, Figure 7 shows the “Test Status” tab with all of the individual tests passing and the overall test status of pass. Figure 8 shows the result of the passing test from the “Detailed Results” tab. The most important information here is the actual measurement data. In the event of a failure, this tab would show you if the test failed high or low relative to the limits or if no meaningful data was gathered (like a test returned NaN). 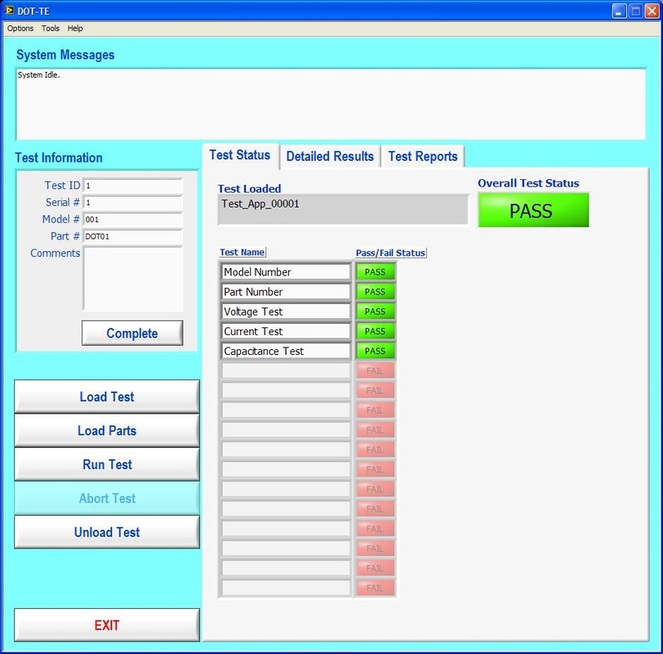 Figure 7. Result of passing test in the Test Status tab view. 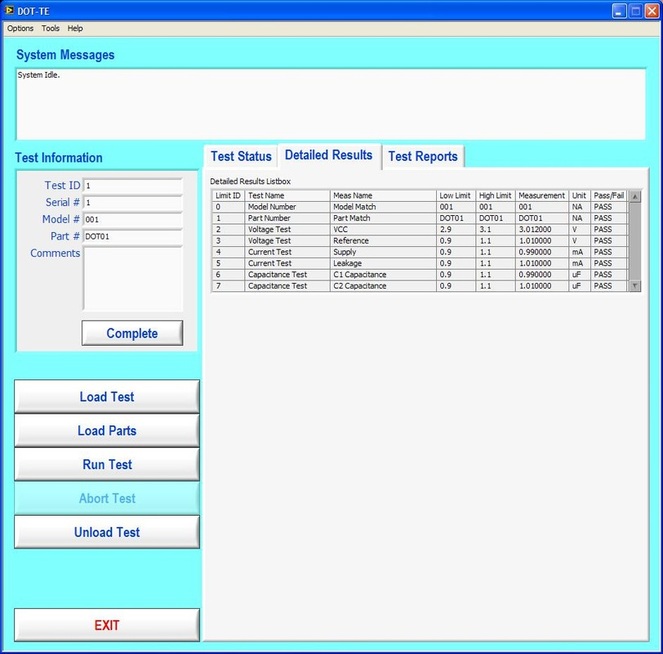 Figure 8. Result of passing test in the Detailed Results tab. At the end of each complete test run an html test report is generated. The test report basically shows the same information that is in the detailed results tab. The history of all the test reports generated since the test executive was opened is in the “Test Reports” tab. Figure 9 shows this. 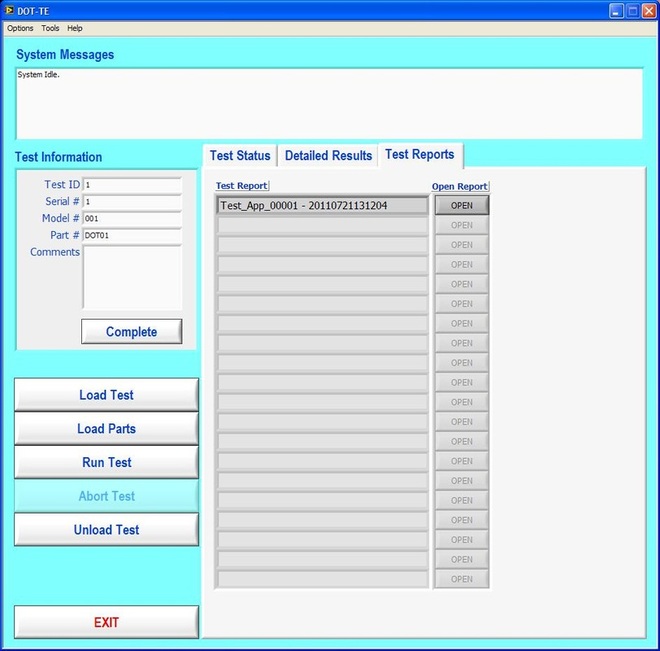 Figure 9. Test Report tab view following passing test. A good enhancement here would be to include the pass/fail status in the test report name. I forgot that. Also, it’s a bit cryptic, but each test report name includes the date and time stamp. At this point, the “Unload Test” button can be pressed and a new test app can be loaded. Or, the “Load Parts” button could be pressed and a new DUT could be loaded and tested. The “EXIT” button unloads the test (if the user forgets to press unload test) and stops the test executive VI running. There are three pull-down menus at the top of the interface: Options, Tools and Help. Options includes sub-menus: Print Setup, Looping, Test Subset and App Directory. Print Setup optionally prints the test report automatically upon test completion. The default is off. Looping is not implemented. Test Subset selects a subset of the tests to run. So, if you have a lot of tests that are very long you can choose to skip some of them. This relies on having an AppSequence file in the test application. Figure 10 shows what is in the AppSequence file. 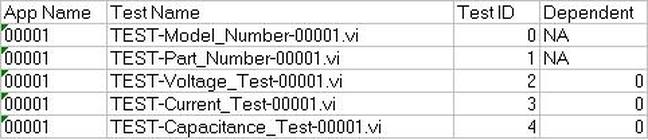 Figure 10 AppSequence file. The AppSequence file also allows dictating test dependency. For example, in Figure 10 if the user tries to run only the test TEST-Voltage_Test-00001.vi without running TEST-Model_Number-00001.vi (where 0 listed in the Dependent column is the Test ID of TEST-Model_Number-00001.vi) an error will be generated from the test executive. The App Directory changes the default location the test executive looks when loading a test application. All options in the Tools and Help menus are not implemented. Implementation I won’t try to go over every detail of the code, if you are familiar with Labview I think it’s pretty simple. Figure 11 shows the project explorer file DOT-TE.lvproj. The project is implemented in one main VI (DOT-TE_Main_UI.vi) with four directories contained all the sub-VIs (Dialog, Globals, Main Functions, Utilities). 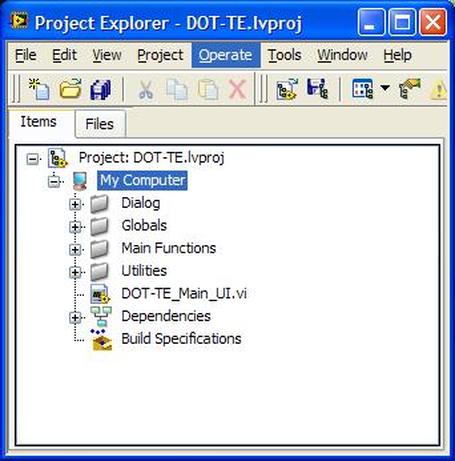 Figure 11. DOT-TE Project Explorer. Figure 12 shows the block diagram of DOT-TE_Main_UI.vi. It may be a little hard to see here, but this is just to see the general producer consumer style. The upper portion contains the event structure that sends a message to the consumer with every button or menu click. The messages are sent with a queue. 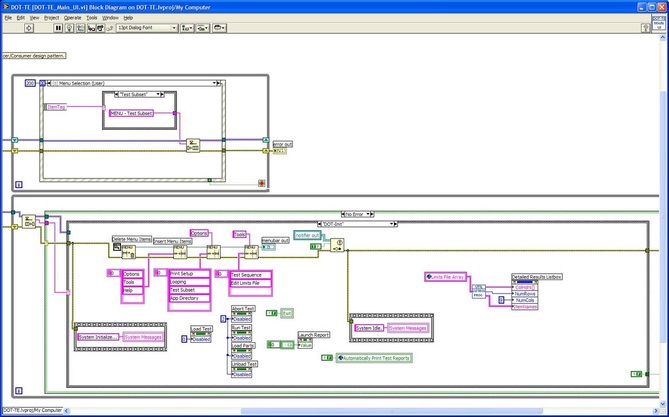 Figure 12. DOT-TE_Main_UI.vi block diagram.
Future Work There is a lot that should happen to this code before it could be really useable. Right now it mostly just demonstrates the concept. There are several places that could be improved. There is no error handling to speak of. The System Messages on the front panel were not implemented. The system messages should be telling the user what’s going on, like when the test is running or the system is waiting on something. Some of the menu features are not implemented. There is very little documentation of the code. Summary A test executive is an important piece of software for a test organization to have in support of manufacturing. While off the shelf test executives exist, there may be cases where a custom design would be worthwhile. The DOT-TE test executive presented here is really about half way done, but it illustrates some important features for a test executive to have as well as some user interface coding concepts in Labview. If we start talking about reliability instead of test engineering we are entering a whole different field of engineering. A test engineer is typically tasked with making sure a product is good when it goes out the door, the reliability engineer is concerned with trying to predict if a product will have a full useful life period. All electronics eventually fail if they are put to use. It may take a few minutes or decades. Since the job of a test engineer is to weed out the failures and defects it’s worthwhile for every test engineer to know a little bit about how products fail. The Bathtub Curve Reliability engineering involves heavy use of statistics and statistical distributions. One of the most fundamental distributions of how products fail is the “bathtub curve.” The idea of the bathtub curve, shown in Figure 1, is that a product goes through three general periods of failure rate. The three periods are, early life or infant mortality, the useful life period and the wear-out period. 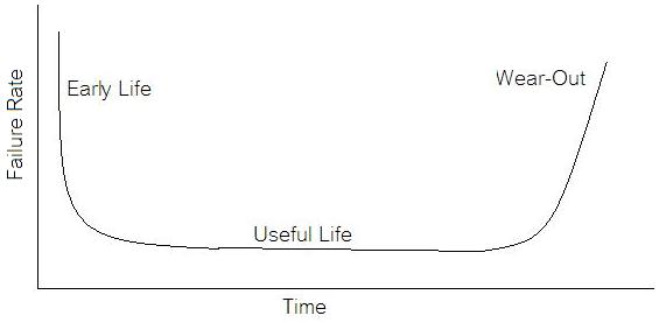 Figure 1. The Bathtub Curve Figure 1 is pretty intuitive, in the early life period the failure rate is decreasing. This behavior is a result of weak products built with manufacturing defects that fail early. When all of those products have failed the failure rate is a constant low value for a long time until the product starts to wear out and the failure rate goes up again. Keep in mind that the curve is the average of a large population of the same product. The early life failure rate still might be very low, but it’s relatively higher than the useful life rate. There is a lot more theory and thought behind the bathtub curve than I’m going to try to go over, because I’m not really concerned with that. There is also some controversy about whether the bathtub curve is realistic or not. The thinking seems to be that the curve could not start out with a decreasing failure rate in the early life period. Even if the early life failures occur very quickly, they did work for a short time and the failure rate should be going quickly up before decreasing (Figure 2). I can see this point, but I think regardless of the most accurate model, the concept of higher, lower, higher failure rates is valid. What I am concerned with is if we accept the idea that there are higher initial failure rates, what can test engineering do about it. 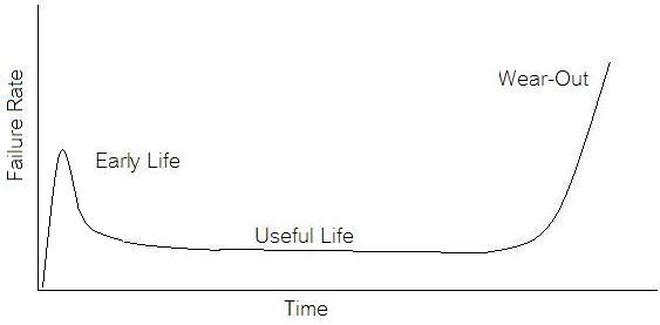 Figure 2. Modified Bathtub Curve: Increasing initial failure rate. Accelerated Life Testing
Accelerated life testing or burn-in are general terms for testing that is designed to stress a product and reveal the early life failures before they can make it to the field. Some techniques include: high temperature operation, temperature cycling, humidity cycling, power cycling, elevated voltage level testing and vibration testing. Burn-In Burn-in, again, is a somewhat broad term. It might mean that a product will operate under normal conditions for some period of time or that it is operated under some set of severe conditions. The idea of operating the product under severe conditions, like high temperature, is to accelerate the process of finding early life failures. It may be the case that performing burn-in tests weakens good products as well as finding the faulty ones. This doesn’t mean that the whole thing is a waste, it can be helpful in determining the general failure rate of the product and the burn-in failures can be analyzed to determine what the underline defect was. It is difficult to determine if it is worth-wile to setup a burn-in test step(s) when a product is manufactured. A big decision when using burn-in techniques is often when to stop. There has to be a trade off between finding the early life failure and just using up the useful life of good products. The cost of setting up a burn-in system should also be considered. Do you want to spend a lot of money and take a lot of time when burn-in just seems like a good idea? There is also a value lost in useful life and time that a product spends in burn-in during manufacturing. To use burn-in you have to have some confidence that the product you are testing will have a higher early life failure rate settling to a low constant later. If the failure rate is just constant or worse always increasing with use of the product, then burn-in is just using up the life of the product and not doing any good to find the weak products. Another criterion for burn-in is the useful life expectancy of the product. Semiconductors can last for decades, but over that time frame they will most likely be obsolete before they wear-out. In this case using up the useful life is not a big problem. Personally, I’m somewhat skeptical of some types of burn-in tests. I think that burn-in is often done simply to give the feeling that everything possible has been done to find failures. If you are working in an industry where the products are hard to replace or man-critical then I can’t really argue too much. But if an occasional field failure is acceptable from time to time, burn-in should be considered more carefully. I also have much more confidence in a burn-in test that performs some type of cycling where materials will be stressed by the changing environment. I’m skeptical of a test where a product is simply operated in constant conditions for some random period of time. Extended Warranty This isn’t exactly a test engineering matter, but knowing a little bit about how products fail gives us some insight into how warranties are used with consumer electronics. The manufacturers warranty usually covers the first 90 days or 1 year, which makes sense and is good, as this should cover the early life failures. However, retailers often want to sell you an extended warranty. Well, the bathtub curve would indicate that this is probably not going to pay off. I also have another way to think about it using a statistical concept called the expected value. Informally, the expected value is what you can expect to happen given two events and two probabilities of those events occurring. Here is the equation: E(x) = x1p1 + x2p2 Where x1 and x2 are some events and p1 and p2 are the probabilities of those events occurring. It’s often stated in the form of a game, like if we bet $5.00 with a 50% probability of winning $5.00 and a 50% probability of losing $5, then what is the average dollar amount we can expect to get? It would look like this: -$5.00(0.5) + $5.00(0.5) = $0 The expected value is $0. Now, if we did this bet only one time we would either win or lose $5.00. However, the idea is to understand of the expected amount we would win or lose if it were possible to make this gamble a very large number of times. It’s pretty simple to see how to evaluate a warranty using the expected value. Let’s say you are going to buy a TV for $500 and the retailer wants to sell you an extended warranty for $100. We don’t know what the probability that the TV will fail will be, but it’s going to be pretty small. Keeping in mind that the larger portion of the failures (early life) will be covered by the manufacturer’s warranty, and then estimate it will fail 1% of the time. The $500 dollars paid for the TV is gone either way. The game to evaluate with the expected value is paying $100 with a chance to “win” $400 (the cost of a $500 replacement TV minus the $100 warranty cost). The expected value looks like this: -$100(0.99) + $400(0.01) = -$95 Pretty good deal for the retailer. For the warranty to start paying off, the percentage of failing TVs has to go up to greater than 20%. It would be remarkably poor quality for a modern piece of consumer electronics to fail 20% of the time after the manufacturers warranty had expired. Declining the warranty, you have automatically accepted the gamble that if the TV fails you will have to replace it at full cost. That would look like this (at 1% failure rate): $0(0.99) + -$500(0.01) = -$5 Either gamble has a negative expected value, but relative to each other -$5 is a much better gamble than -$95. Summary The bathtub may not be a perfect model, but is a useful concept for a test engineer to be familiar with. Accelerated life testing and burn-in, when carefully considered, are an important test strategy tool for test engineering and insuring product reliability. I have previously written about how to do some basic things with the PXI instruments I have been working with lately. While I covered using the DAQ to generate and acquire analog signals, I would like to expand on what I wrote there. The NI PXIe 6259 M-series DAQ has three kinds of pins, or physical channels, as NI calls them. There are analog I/O, digital I/O and counter pins. The pins are setup like this. 32 analog inputs (ai0…ai31) 4 analog outputs (ao0…ao3) 64 digital pins (Port 0/line 0 to 31, Port 1/line 0 to 7, Port 2/line 0 to 7) where all of these pins are on Dev1. Dev1 is the DAQ, so if you added another DAQ to the PXI chassis it would be Dev2. Port 1 and 2 are arranged like this 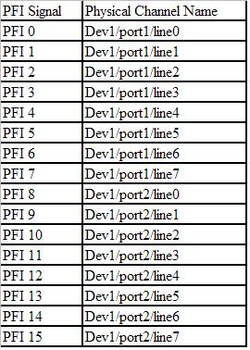 2 counters arranged like this  There is also PFI 14 which is FREQ OUT, used as a simple output only frequency generator. PFI stands for “Programmable Function Interface,” which is just a designator they gave it to mean it does something. There is some overlap between the digital pins and the counters. For example, PFI 4 is a dedicated digital pin used for ctr1 gate on counter 1. Digital I/O Example code written to demonstrate digital I/O of the DAQ is shown in Figure 1. The code uses the DAQmx driver to configure a digital input, output and clock signal. The output generates a sequence of digital values and reads them back in on the input when looped back through the matrix PXI card. Counter 0 is configured to be a clock signal where the frequency, duty cycle, initial delay and idle state of the clock are configurable. The digital input is setup to trigger off the clock signal and start acquiring data. The digital output is also setup to trigger off the clock and start generating the programmed data pattern. Notice that the digital output is set to update on the rising edge and the input on the falling edge. This will allow the output level to stabilize before it is read by the input. The clock, digital in and out are all configured to operate with a finite number of samples, 16 used here. It’s a little confusing, but in this case number of samples means clock pulses. Each of the clock, digital input and output are configured with their own task. The input and output tasks are started immediately after the channel is configured, in effect arming the channel as it does not really start until the trigger clock signal is received. Finally, the clock from the counter task is started. This starts the clock sequence and the code waits until the clock is finished allowing all of the digital data to be output and acquired. If I somewhat understand the NI terminology, a channel is created and controlled with a task. For example, you create a digital output channel and then any other code after that related to the channel has to be wired up to the use the same task where the task was created. You can also give the tasks meaningful names to help organize the code. It was a little confusing at first but become pretty intuitive quickly. I guess it’s like the instrument VISA session handles that some older NI drivers used, but you can use multiple tasks within the same instrument.  Figure 1. Digital pattern example block diagram Figure 2 shows the front panel of the code. 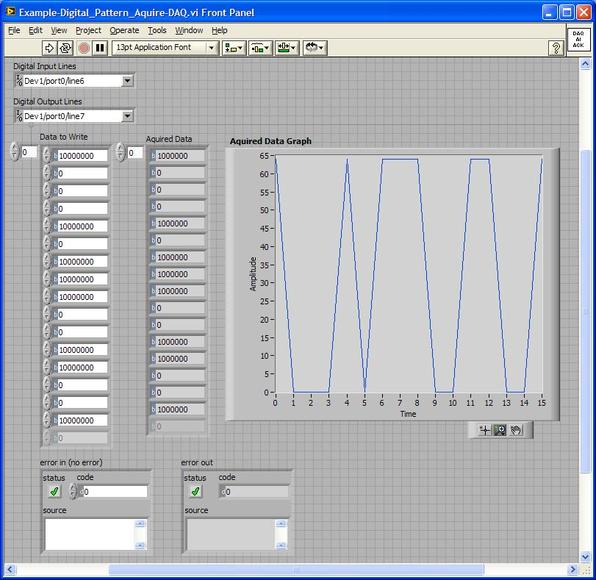 Figure 2. Digital pattern example front panel. In Figure 2 notice that the output and input are configured with only one line, where line 6 is the input and line 7 is the output. These are just arbitrary choices. What is significant is looking at the “Data to Write” array control, in order to set a value of 1 on the output line 7, I need to put a 1 in the 7th bit position (LSB on the right). “Data to Write” is formatted in binary to show this but really the driver accepts a U32 that covers the whole port. The same is true for a 0 value, Labview formats 00000000 as just 0 so it looks a little different than the 1. Also notice, the input line is line 6 so now the bit has moved a position in the “Acquired Data” indicator. You can also see on the graph that the Y axis is in decimal so a high value shows up as a 64. This would probably be a good place to create a new driver where if you are programming a single line only, you don’t have to keep track of the bit position. It’s pretty interesting because there are a lot of possibilities of how you can use this. With some pre-processing you could send a bit stream into a single line (basically, what is happening here) or you can program the whole port at once by just creating a channel as Dev1/port0 rather than Dev1/port0/line7. As also shown, you can split up the port so some of it is configured as input and some as output. Counter The digital I/O example made use of the counter as a clock to synchronize and trigger. The counter can also perform the operations typically associated with a counter, like measuring frequency, period and counting edges. Figure 3 shows the block diagram of an example using the counter to measure frequency. 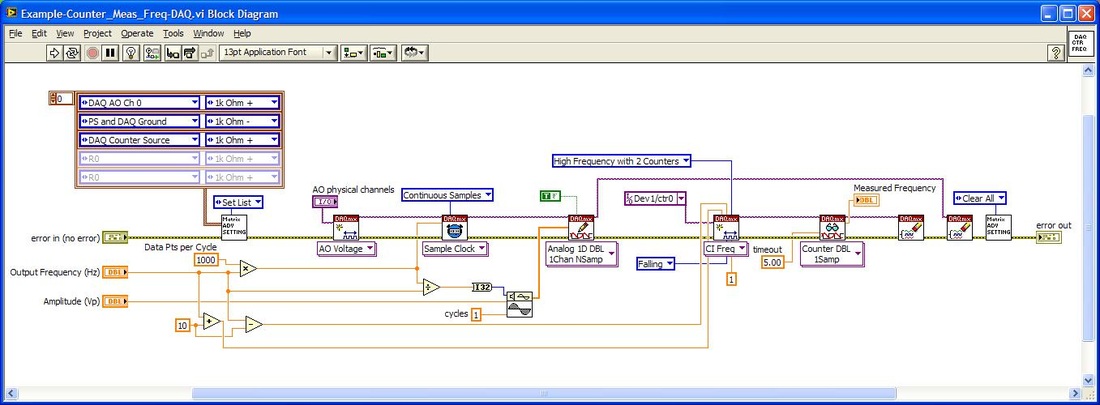 Figure 3 Block diagram measure frequency using DAQ counter The code is very simple. An analog output is connected to a counter input through the matrix. The analog output is configured to generate a sine wave and the counter is configured to measure the frequency. Notice that the programmed sine wave frequency is used to create a max and min value, plus/minus 10, of the measured frequency. This is wired into the counter configuration for accuracy. Figure 4 shows the front panel of the same code. 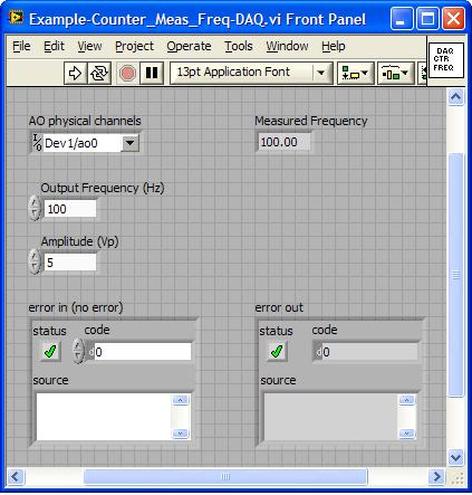 Figure 4. Measure frequency with DAQ counter front panel.
You can see in Figure 4 that the analog output frequency was programmed to 100 Hz and 100 Hz was measured with the counter. Summary This article showed some examples of using the NI PXIe 6259 M-Series DAQ. In addition to analog inputs and outputs the DAQ includes multiple digital I/O lines that could be used in a number of flexible ways. The counter is an additional useful instrument included with the DAQ. The DAQ is marketed as the all-purpose instrument and that’s what makes it interesting to work with. A DAQ can replace a number of more specialized PXI instruments like DMMs and function generators or it could be used to implement very specific high level cards like boundary scan controllers. When talking about debugging people might think of debugging code, and while that is part of it, I’m referring to the larger problem of solving test issues no matter where they are found. Perhaps trouble-shooting is the correct term, but either way every test engineer has to do it and it can be a difficult skill to learn and perform effectively. Debugging mostly comes down to being able to think logically, but it’s not just something you are born with you have to learn (and usually the hard way) by doing it over and over until it becomes natural. I don’t think debugging is something that normal people (normal people are non-engineers) are very good at and a lot of engineers are not even all that good at it. It’s not really their fault; they just haven’t had enough practice. Despite all this, there are some tips to keep in mind while debugging, these are the type of tips that are easy to know but not always easy to follow. There are two main situations where a test engineer has to debug something. - Debugging problems that occur during test hardware and software development - Debugging unexpected problems that occur during manufacturing after you think you are done. These are more serious problems and often much more difficult to solve. Below these two categories there is another division of either a constant or intermittent problem. From there, most of the debugging techniques used are the same. The constant type is much easier to solve than the intermittent type. Intermittent test problem I’ll start with the more difficult type of debugging task, trying to find an intermittent test problem. These problems are usually revealed due to the increased volume when a test is initially being run in manufacturing. When faced with an intermittent failure like this, the first thing I usually do is look at the test report and try to see if it’s telling me anything. Is the problem that the test fails a limit or is there some software error being generated? If it is a limit failure that might just be a bad part and the part might need to be retested or otherwise analyzed. If it’s a software error, I’ll think about the error in the context it occurred and see if there is some reason for it. Like is an instrument giving an error because it’s trying to measure out of range. So, if you eliminate these obvious things and the DUT seems good, you have a true intermittent failure. It may fail every other time or 1 in 1000 times, either way it’s time to get in the lab and debug the problem. Recreate the problem Before you can fix the problem you have to understand it and to do that you have to be able to recreate it. It is sort-of Murphy’s law that these things be difficult to recreate, but you can’t really be sure the problem is fixed until you can cause it to happen and then apply your fix to prove the problem is gone. It’s quite possible that recreating the problem will be the bulk of the work because you will end up understanding what it going on if you can recreate it. When trying to recreate a problem you often fall into the following pattern. - Looping the test - Look for patterns in the looping data - Change something - Loop again Looping the test means to setup the test to run over and over on the same DUT and test system setup until it fails. You probably won’t learn anything just by looping until the failure happens again. You take measures to gather more information in the event of a failure. For example, maybe you suspect a noise signal causing a problem so you set up a scope to trigger on a spike and see if is the scope shows anything upon failure. Or, you modify the code to stop on a breakpoint when the failure occurs and hopefully the DUT is left in a state where the problem can be repeated. These are the ways you gather clues to see what was different about the test run on the times it failed. When you change something you are hopefully affecting the failure rate, with the goal of making it fail every time. This might seem strange, because you might think that change the test so that it fails is just breaking it. What you are doing it trying to exacerbate a situation to make the intermittent failure occur all the time or at least more often. If you can make it fail more often you know you are maybe on the right track. An example might be that in a test you provide power to a DUT and program a delay into the code to allow the DUT time to reach steady state. Maybe this delay is just on the borderline, so that when you were developing the code you never saw the problem but really 1 out of 100 times it is a problem. So, you can make the problem worse by shortening the delay and seeing if the failure occurs more often in the looping. Change one thing at a time This is important, when you change something, just change one thing at a time. This is a hard rule to follow, especially if you have to loop in-between because you have to be so patient. Also, if you change something and it doesn’t have an effect, change it back before you change something else and try again. If you don’t do this you can get lost very fast, because now you don’t know if the latest change or the combination of the latest change and some previous change is making the difference. Take small steps In addition to only changing one thing at a time, change things in small steps if possible. Let’s say that you are looking for a glitch on a signal by monitoring it with an oscilloscope. Say you are changing some parameter of a test like a delay or a voltage. You might think to try a low voltage and a high voltage and this does not appear to have an effect, but really you have missed some behavior that is a clue by jumping the voltage too fast. Take small steps. Ask for ideas If you have a collogue who will listen, it helps to run through the problem and all the things you have tried with them for some ideas. They may know something about the system you don’t or might have some ideas that didn’t occur to you. However, you have to know who you are asking, that they have the skills to help and that they will be willing to help without trying to take over. Think about the assumptions Think about the assumptions you are making. Do you really understand everything you think you do? Are you assuming that the problem is not related to a certain piece without having proved it? Write everything down Keep track of what you have tried, it sounds silly but you can go crazy pretty fast on a tough problem and just start spinning your wheels. Look back at what you have done and this will help you to think logically and see patterns. Nothing works It is quite possible that you will not be able to make the problem worse and make the problem repeatable. All the debugging techniques like only changing one thing at a time and taking small steps still apply. However, you are stuck in the change, loop, wait cycle which is much slower. Really if you are able to recreate the problem, you are most likely 90 percent of the way to solving it. Isolate the problem Once you can reliably recreate a problem or you have a repeatable problem to begin with, you can start using a logical process of elimination. Is the problem in hardware or software? Is it the DUT or the test system? You have to start crossing things off the list and narrow it down. It is much easier to debug if you have multiple instances of all your hardware, that way you can swap them in and out to hopefully isolate a problem. Here is an example of the process of elimination. A test system is a complex system. A problem can be in the DUT, the tester the ITA, the fixture or the software. It’s just a flow chart. See Figure 1. 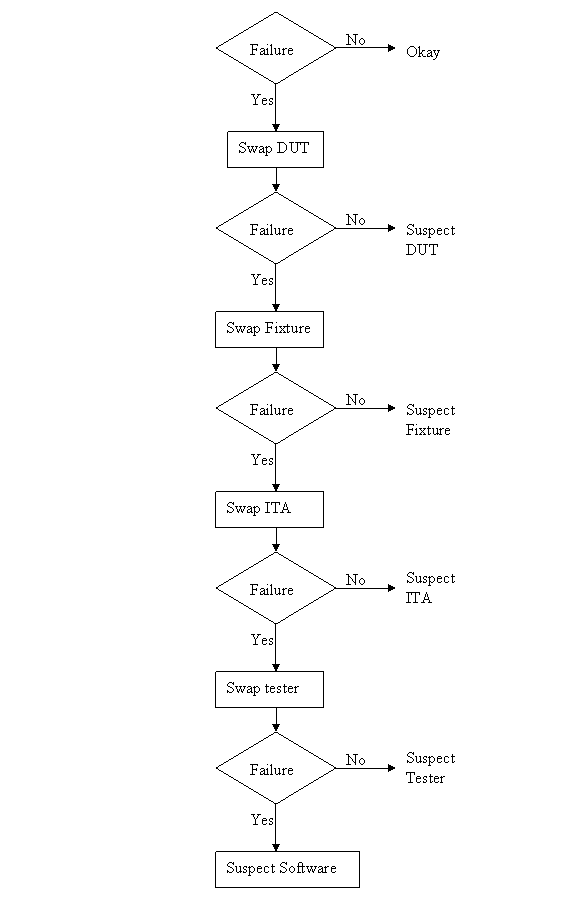 Figure 1. Isolating a problem among test system components. Recreate the experiment Once you think you have recreated the failure or found a pattern where if you make a certain change it has a certain effect, then try it all again. That is, turn everything off or take apart the setup and try to recreate the whole thing. Make sure your experiment is repeatable. I’ve had it happen many times where I thought I had a pattern only to have it go away when I start again. This is the type of thing that happens if you make more than one change at once and forget about the changes you have made. Prove it another way Try to prove everything two ways. So, when you think you have a pattern figured out try to think of another way to prove it that is independent. Maybe you found some noise on a digitized waveform, try to see the noise on an oscilloscope to make sure it’s real. You will ultimately have to convince someone you have found and solved the problem, this second proof will strengthen you case. Example I recently had an opportunity to do a simple debugging task at home. Granted, this is very simple, but it somewhat illustrates the debugging process. I have an old DirecTV DVR receiver that was often having the signal on Input 2 break-up. (a DVR has two coax inputs so you can record two shows at once) Figure 2 illustrates the setup.  Figure 2. Satellite TV with DVR setup
The first thing to do is to make sure you know what problem you are trying to solve. In this case, the problem is that picture on Input 2 is goes out and breaks up intermittently. Next, I had to think of all the things that could be wrong and start eliminating them. So, the Satellite dish on the roof might have a problem, Cable 2 might be bad. The input or tuner on the DVR might be bad. I’m hoping that the result is the DVR is bad because it’s over five years old and ready to replace anyway. This is my main suspicion because as crazy as it may sound I’m sure five years is a remarkable amount of time for a piece of consumer electronics to last. Also, it seems logical as this is by far the most complex piece of the system. Having thought it through this far, the objective is now to prove that if I replace the receiver that it will work and that will fix the problem. The first thing I tried was to check the signal strengths of the two inputs using the DVRs menu. It said 95% on input 1 and 87% on input 2. Hmm… that doesn’t tell me that much. While this doesn’t rule out the DVR it probably means the dish and cables are fine. It is interesting that input 2 is a little bit lower, that might be just a random result. At this point I had a much better idea, if I switch the two cables going to the DVR and the problem stays on input 2, then the DVR is the problem. If I switch them and the problem follows to input 1 then the cables or dish are the problem. Well, after switching them the picture on input 2 was still breaking up confirming my suspicion of the DVR input 2 being bad. I have since replaced that DVR with a new one and it is working great. Of course I never really got to the root cause of the problem with the DVR, but in this case I don’t really care and it may not be possible to find that without more information about the DVR itself anyway. Summary Debugging is a difficult task because this is how you tackle the most difficult problems. There are some concrete techniques to keep in mind when debugging. The keys to debugging are being patient and methodical. Write down what you have tried and try to think as logically as you can. It’s interesting that often times you will amass all these clues that seem to mean things or are patterns and some of them seem to contradict each other. When you finally figure out the root cause and really understand what’s going on, everything makes sense. You find yourself seeing the light and all the pieces fit. That’s a good feeling. Recently I’ve been developing a PXIe 1065 chassis based test system using Labview. The chassis includes an 8150 controller, a matrix card, a DMM, a DAQ and some power supplies. It’s a fairly simple set of instruments, but capable of many types of measurements. National Instruments supplies drivers to operate these cards but they require some effort to learn how to put them all together and create working test applications. I’d like to show some examples of how to make some basic measurements and some methods I feel are useful to improve on the supplied drivers. Note that this isn’t the real code I’m writing for my employer since I don’t want to give away any secrets or anything, but it is real working code. Initialization Before any of the instruments can be used to make measurements they all have to have instrument handles established. A good way to do this is by having a test application run an initialize routine that will create instrument handles for all of the instruments and hold them in a global variable. Figure 1 shows the block diagram to initialize the instrument handles for the Matrix, DMM and Power Supply and stores them in a global to be utilized by the application code later. The DAQ is not included, as it doesn’t require a handle to be initialized. The DAQ driver is a little different than the others; I’ll address this later. Figure 2 shows the global variable used to store these handles. 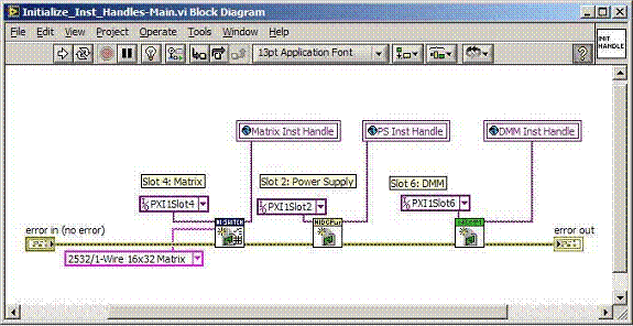 Figure 1. Initialize instrument handles for PXI instruments. 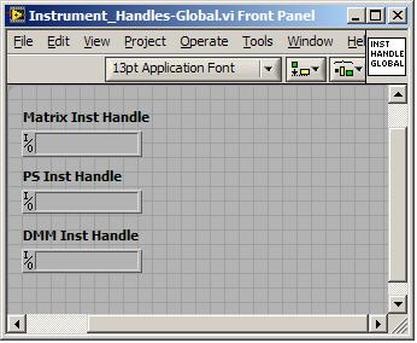 Figure 2. Global variable holding instrument handles (shown un-initalized) Matrix The matrix card is used for switching the instruments to the DUT. I’ve been working with a PXI-2532 16 by 32 crosspoint matrix. Additional hardware has been added as an ITA to make hard connections from the matrix inputs to the other instruments in the chassis as well as the DUT. That is, before you can use the matrix you have to wire the other instruments to the matrix inputs and wire the outputs to your test fixture and ultimately, DUT. Here is where the instruments are connected to the inputs of my system (omitting a couple I’m not discussing) 0. NA 1. NA 2. DMM V+ 3. DMM – 4. DAQ Counter Source 5. NA 6. NA 7. DAQ Analog Out Ch 2 8. DAQ Analog Out Ch 1 9. DAQ Analog Out Ch 0 10. Power Supply Out 2 +20V 11. Power Supply Out 1 +6V 12. Power Supply and DAQ Ground 13. Power Supply Out 3 -20V 14. DAQ Analog In Ch 0 15. DAQ Analog In Ch 8 The two essential Matrix drivers supplied by NI are Connect and Disconnect VIs, as shown in Figure 3. 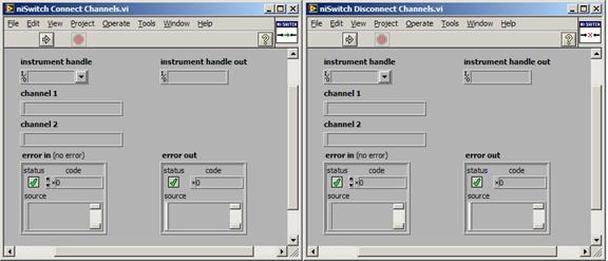 Figure 3. Connect and Disconnect driver front panels. Both VIs simply take the channel 1 input as the matrix input and the channel 2 input as the matrix output you want to connect or disconnect. For the 2532 matrix the input channels are R0…R15 and the output channels are C0…C31. Figure 4 shows and example of connecting the DMM at inputs 2 and 3 to outputs 1 and 2. Let’s say there is a 1k resistor at outputs 1 and 2. 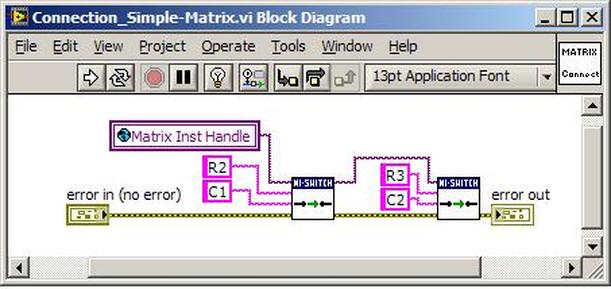 Figure 4. A simple matrix connection The code in Figure 4 will work but it’s not very flexible and it is pretty cryptic as to what is being connected. Some comments could be added to the code to say that the DMM is connected to a 1k resistor. But, a better way would be to create a new driver and give all the inputs and outputs meaningful names using some enumerated types. With a little more work a much more flexible Matrix control can be developed. Then new driver is called, Settings_Advanced-Matrix.vi. Unlike the simple code in Figure 4, it contains three modes: Set List, Clear List and Clear All. It also provides the ability to set multiple input to output pairs at once by accepting an array as input. The input and output designations have been given unique names as controlled by some strict type def controls. The advantage of the strict type defs is that the matrix input and output designations can be updated in one place and all instances of the control elsewhere will update as well. Finally, the code allows for relay debounce by calling the NI driver, “niSwitch Wait For Debounce.vi.” Figure 5, 6 and 7 show the block diagram of Settings_Advanced-Matrix.vi in the three modes. 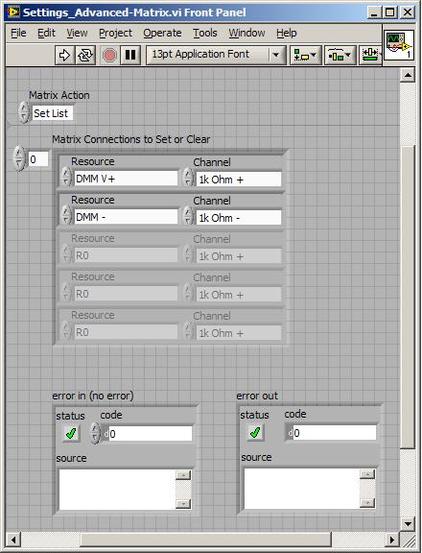 Figure 5. Front panel of Settings_Advanced-Matrix.vi 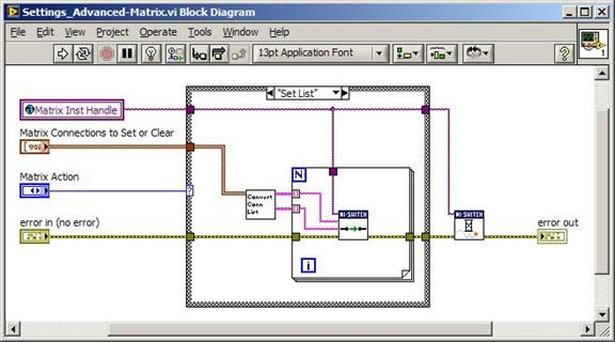 Figure 6. “Set List” mode of Settings_Advanced-Matrix.vi 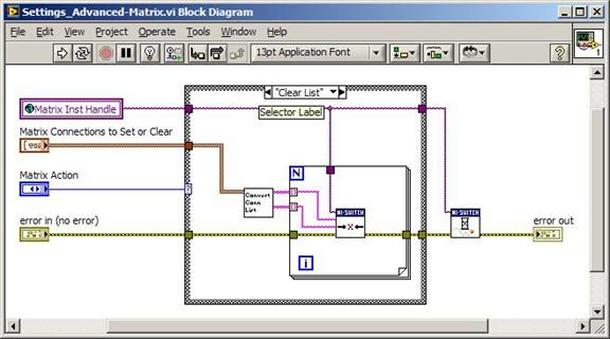 Figure 7. “Clear List” mode of Settings_Advanced-Matrix.vi 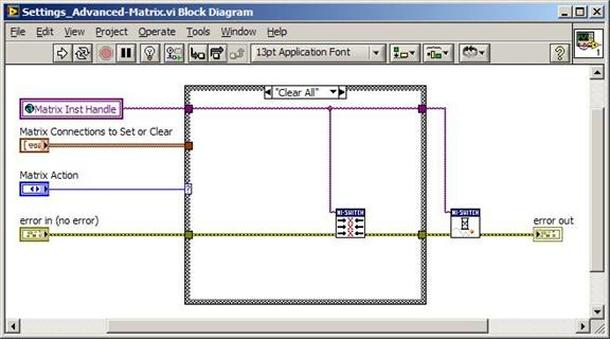 Figure 8. “Clear All” mode of Settings_Advanced-Matrix.vi In Figure 5 you can see the “Matrix Action” enumerated type control that allows the selection of “Set List”, “Clear List” or “Clear All.” It also shows that the VI has the ability to set multiple input to output connections at once and that the inputs and outputs have been assigned meaningful names. Figure 9 and 10 show the strict type defs used for the input and output names. Figure 6 and 7 show the use of a subVI called Convert_Connection_List-Matrix.vi. This VI is shown in Figure 11. 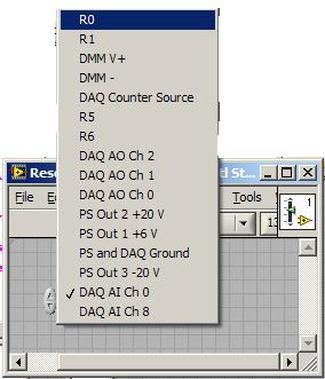 Figure 9. Resource (inputs) control strict type def 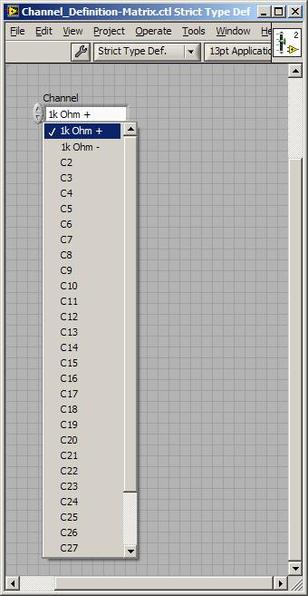 Figure 10. Channel (outputs) control strict type def 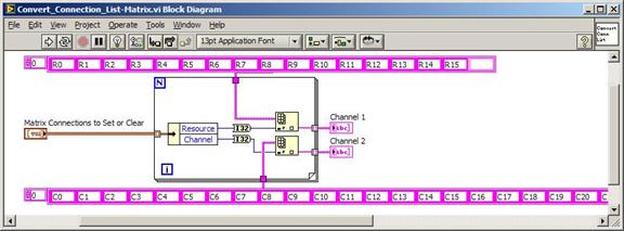 Figure 11. Convert Connection List block diagram Figure 11 shows how the array of meaningful resource and channel names are processed and replaced with the R0… C0… names that the NI driver uses. An additional enhancement that might be considered is if a certain combination of connections could cause damage to the instruments, error checking to prevent those combinations could be added. DMM Now that there is some code in place for making matrix connections we start using some of the other instruments present in the system. The DMM in the system is an NI PXI-4071. For the case of the DMM the drivers supplied from NI are pretty good, they could be wrapped but for my purposes here they will do. Figure 12 shows the block diagram of how to measure the 1k ohm resistor that is at outputs 1 and 2 of the Matrix. 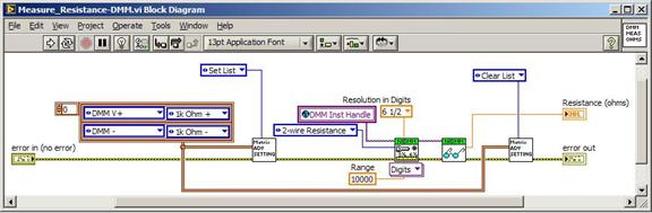 Figure 12. Measure resistance with a DMM through the Matrix. We can see in Figure 12 that the VI, Settings_Advanced-Matrix.vi developed in the last section is used to connect the DMM to the 1k ohm resistor through the matrix. The resistance is measured using the NI drivers niDMM Configure and niDMM Read. Finally, the matrix settings are cleared upon exiting the VI. A good way to ensure you have cleared the same relays you set is to wire the same constant to the set and clear matrix drivers. Figure 13 shows the front panel of the resistance measurement, showing that the VI read 1k ohms (note this is a 5% resistor and that is why it’s off from 1k) 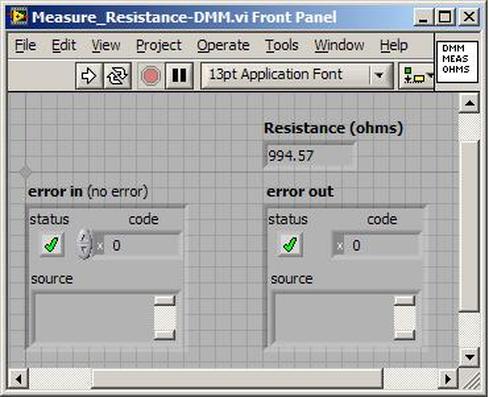 Figure 13. Measure Resistance Example. Now, let’s work in the power supply and use the DMM to measure voltage and current. Figure 14 shows an example of how to use the power supply to force current through the 1k ohm resistor and measure the resulting voltage across the resistor. 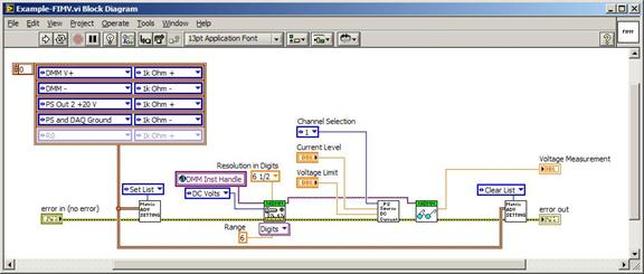 Figure 14. FIMV using the power supply and DMM. Following the code in Figure 14 we see that the matrix is setup to connect the power supply and the DMM to the 1k ohm resistor. The function, resolution and range of the DMM are configured followed by the power supply being set to source the current. Finally, the voltage measurement is taken with the DMM and the matrix settings are cleared before exiting. Figure 15 shows the front panel of the FIMV example. 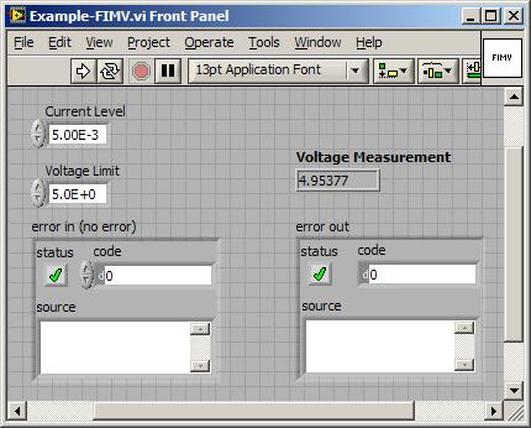 Figure 15. FIMV Example front panel. From Figure 15 we can see that when forcing 5mA through a 1k ohm resistor the result is roughly 5V. Figure 16 shows the code to force voltage and measure current. 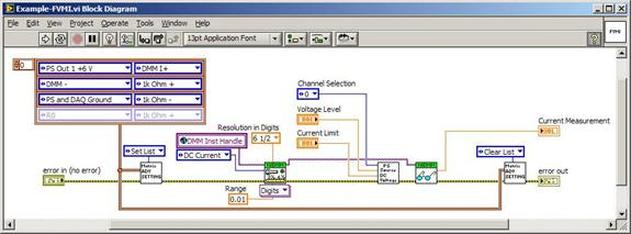 Figure 16 FVMI Example block diagram. In Figure 16 we can see that the matrix settings now apply the power supply to the 1k ohm resistor with the DMM connected in series with the positive power supply lead in order to measure current. The DMM is configured for range, function and resolution, the power supply is configured to force voltage and set the current limit, the current is measured by the DMM and the matrix settings are cleared. Figure 17 shows the front panel of the FVMI example. 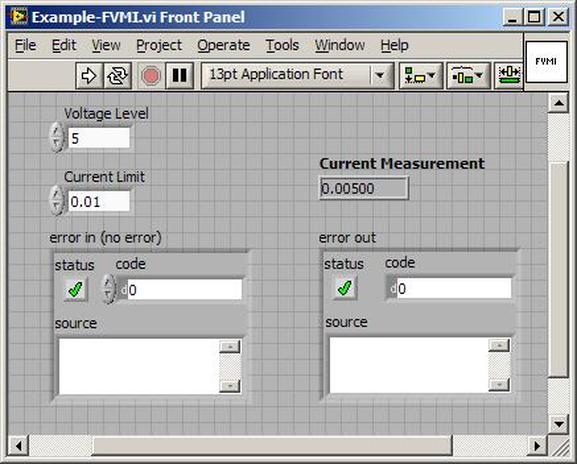 Figure 17. FVMI example front panel. From Figure 17 we see that when 5V is applied to the 1k ohm resistor with a current limit of 10mA, the result is 5mA. Figure 14 and 16 show that I didn’t really develop drivers for the DMM to configure them to measure DC voltage or current, I just use the NI supplied drivers. However, for the application of digitizing a waveform a driver is worthwhile to develop. Two VIs were developed to configure and perform a digitization, Figure 18 shows the block diagram of the digitize configure. 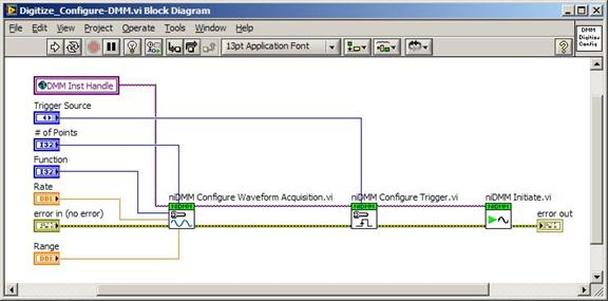 Figure 18. Digitize configure DMM driver. In Figure 18 we can see that there are three NI drivers used. The first is the configure waveform acquisition, this configures the DMM to digitize. Configure trigger, sets the trigger source to various trigger sources like, immediate or external. Finally, the initiate VI tells the DMM to arm and wait for the trigger. Figure 19 shows the front panel of the digitize configure DMM driver. 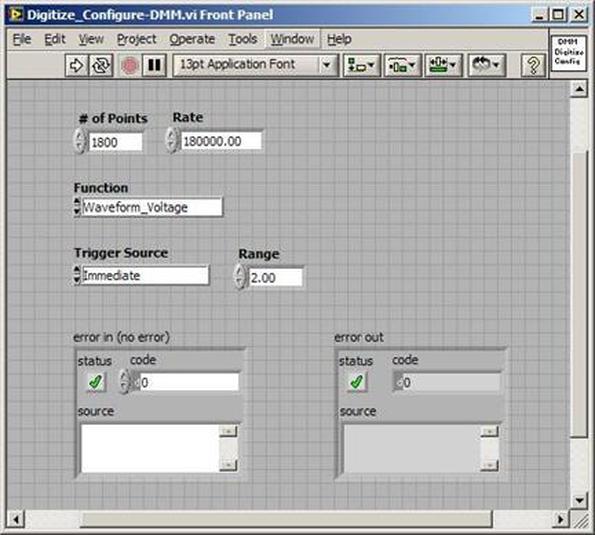 Figure 19. Digitize configure DMM driver. Figure 19 shows all the options that can be set for configuring the DMM to digitize. Most of the options are obvious, the rate is the number of sample per second. The range is the measurement range in the units that match the measurement function. Figure 20 shows the diagram of the digitize VI. 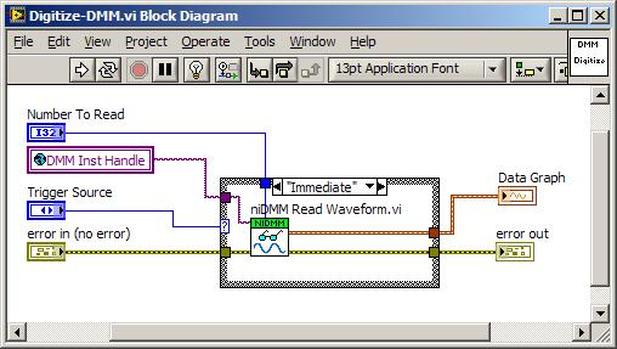 Figure 20. Digitize VI Block Diagram. Figure 20 shows the code that will send the instrument a trigger based on the trigger source and perform the digitization. Figure 21 shows the front panel of the digitize VI with a digitized sine wave being displayed. 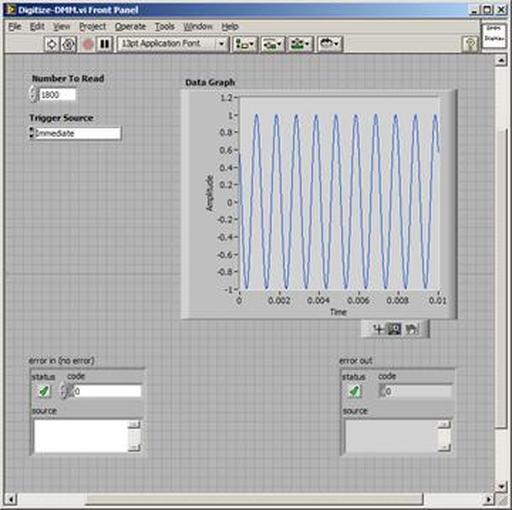 Figure 21. Digitize front panel. Figure 22 and 23 show an example of how to use the digitize drivers with some of the other code that has already been developed to digitize a sine wave. 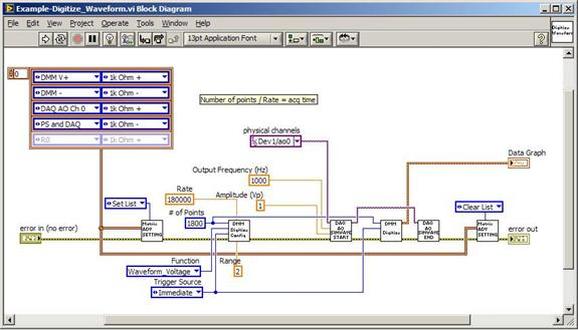 Figure 22. Digitize sine wave example block diagram. 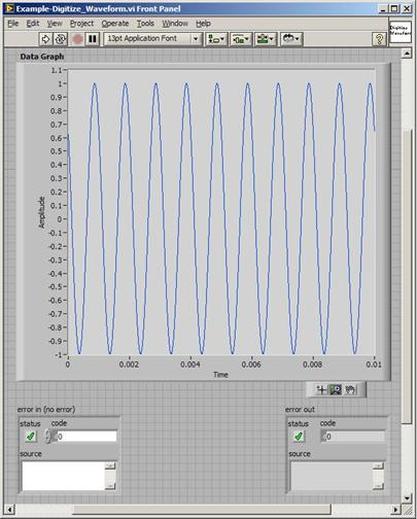 Figure 23. Digitize sine wave example VI front panel. Figure 22 shows the following operations to generate and digitize a sine wave. The first step is to connect the DMM and the DAQ analog output across the 1k ohm resistor. Next, the DMM is configured to digitize for 10ms and the DAQ starts to output a sine wave at 1kHz. Finally, the waveform is digitized, the sine wave output is stopped and the matrix settings are removed. We can see in Figure 23 that since a 1kHz sine wave has a period of 1ms and 10ms were digitized there are ten cycles digitized. Power Supplies While we used the power supply drivers in the FVMI and FIMV code in the DMM section to force the voltage and current we did not look at that code. The system contains the NI PXI-4110 power supply. Figure 24 shows block diagram for the Source DC voltage VI. 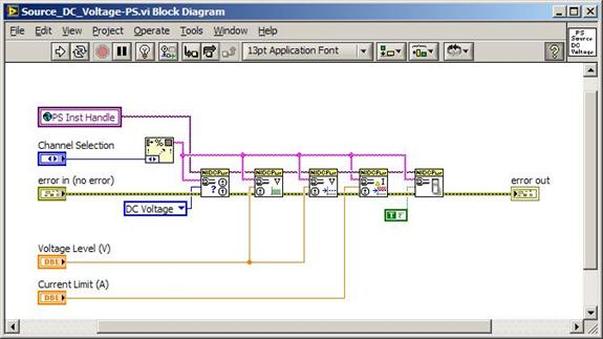 Figure 24 Force DC Voltage block diagram. Figure 24 shows all the NI drivers used to configure and output DC voltage with the power supply. First the power supply function is selected, followed by setting the voltage level and range (the range is automatically set to a predefined level based on the desired voltage level). The current limit is then set and the output enabled. Figure 25 shows the force DC current block diagram. 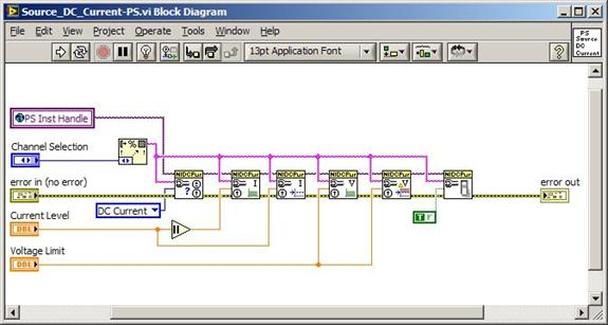 Figure 25. Force DC Current Block Diagram. Figure 25 shows a similar procedure as to set DC voltage. Set the function, set the level and range, set the voltage limit and enable the output. DAQ Again, in the DMM section the DAQ was used to generate a sine wave to digitize but this code was not examined. The system contains a 6259mx m series DAQ. Figure 26 and 27 show the DAQ drivers used to start and stop generating a sine wave. 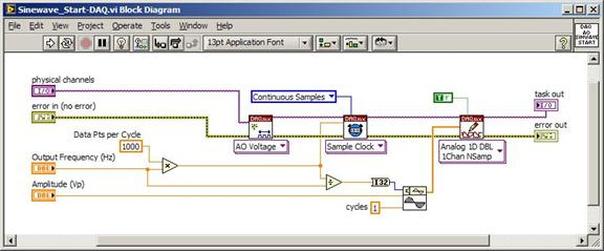 Figure 26. Sinewave Start DAQ VI. Figure 26 shows that it takes three steps to configure a DAQ analog output. First, a physical analog output channel must be selected and configured to output voltage. Next, the sample clock is configured to output data-points at the desired rate. Finally, a sine wave pattern is generated in software and programmed to the DAQ to be output at the previously programmed clock rate. This VI will begin outputting the waveform continuously as the sample clock was programmed to continuous samples. Figure 27 shows the sine wave stop VI. 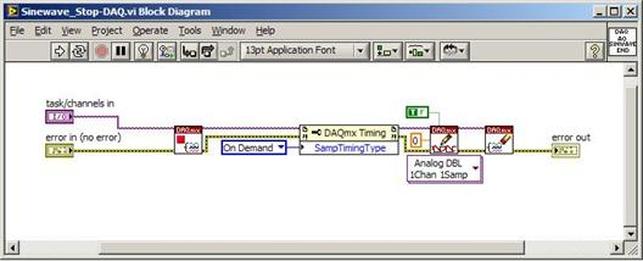 Figure 27. Sinewave Stop VI block diagram. The steps to stop the DAQ output shown in Figure 27 are to stop the task, write a zero to the analog output voltage and clear the task. Figure 28 shows the block diagram of an example of how to use the DAQ to digitize a waveform. 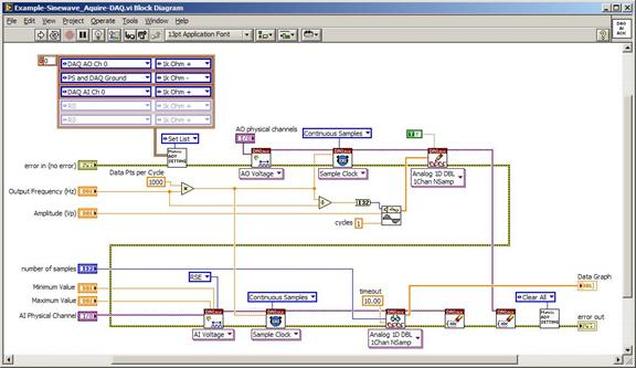 Figure 28. Example of waveform generation and digitization with the DAQ. In Figure 28 we can see that the matrix is used to connect a DAQ analog input to analog output through the 1k ohm resistor. The code to generate the sine wave is the same as from the DMM digitization example. The new code is used to digitize on the analog input and is very similar to the code used to generate the waveform. Replace the analog output channel with an analog input channel. Replace the write channel VI with the read channel VI. Finally, clear both tasks and remove the matrix settings. Figure 29 shows the front panel of the code in Figure 28. 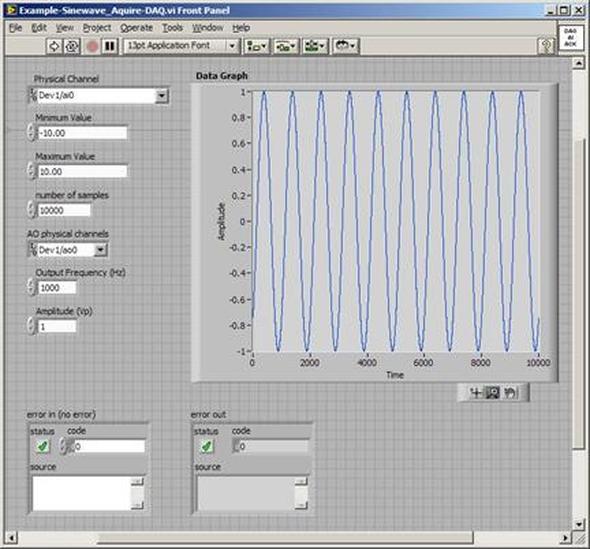 Figure 29. Front panel of digitize waveform with DAQ example
Summary PXI has become the standard for rapid development of flexible, low cost automated test systems. National Instruments with its Labview development environment is the industry heavyweight behind PXI based test. NI provides drivers for their PXI card instruments, however, these drivers can take time to learn and can often require additional work to make them robust instrument drivers. In this entry we saw some examples of how to build these drivers and how to use them to create some useful instrument functions. Some examples included, outputting voltages and currents, connecting instruments via a matrix card, generating waveforms and digitizing waveforms. I have previously written about digital boundary scan or IEEE Standard 1149.1. Analog boundary scan falls under IEEE Standard 1149.4 and is an extension of 1149.1 (it's actually called the mixed signal standard). While digital boundary scan is all about setting test bit values at inputs and output cells, analog is similar but adds test cells that interface with a test bus that can be used to route out internal analog signals to be measured. Analog boundary scan allows access to analog circuit nodes that may not be available through more traditional in-circuit test access. It allows parametric measurement of external components attached to IC or SOC pins along with the ability to hold or control the analog values going into the system at the pins. The trade off of is that the circuitry must be designed and implemented correctly at an increased cost. Figure 1 shows the basic parts that make up analog boundary scan when implemented. 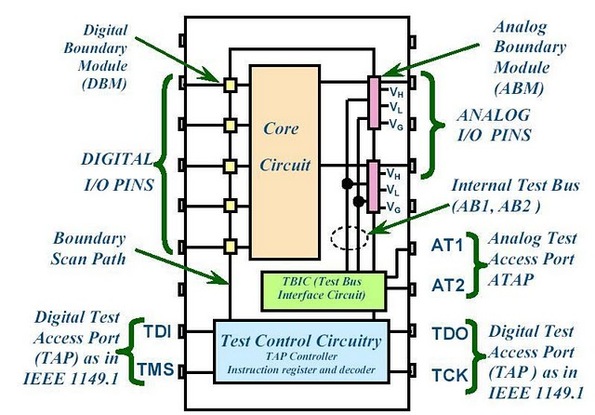 Figure 1. Analog boundary scan system. Referring to Figure 1 there are several components to notice. The system still contains digital boundary scan cells and the TAP controller. What is new is the TBIC (Test Bus Interface Circuit), the analog test access port (ATAP) with pins AT1 and AT2, the internal test bus (AB1 and AB2) and the Analog boundary modules (ABM). Analog Test Access Port (ATAP) The ATAP is made up of two pins, AT1 and AT2, which make up the external access to the analog boundary scan system on a chip. These pins are used to either read or apply analog signals into the chip. Test Bus Interface Circuit (TBIC) Figure 2 shows the internal switching of the TBIC. 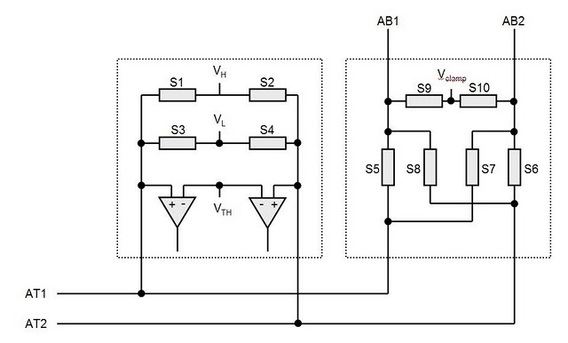 Figure 2. Internal switching of the TBIC The TBIC is the switching (S5, S6, S7, S8) connection between the external analog boundary scan pins (AT1, AT2) and the internal test buses (AB1, AB2). The switches S9 and S10 allow the option to clamp the test buses AB1 and AB2 to a set voltage. These switches along with Vclamp can be used as noise suppression when the test buses are not in use. Also available is the ability to set the buses to either a high or low voltage via VH and VL. A threshold can be monitored on the test buses by comparing them to Vth. Internal Test Bus (AB1, AB2) The internal test bus is the connection between the TBIC and the analog boundary modules. It provides a method to read or write analog signals from the ATAP through the TBIC and on to the ABMs. Analog Boundary Modules (ABM) Like digital boundary scan modules, these modules are serial with the input and output pins of the IC. Figure 3 shows the details of the input portion of an ABM. 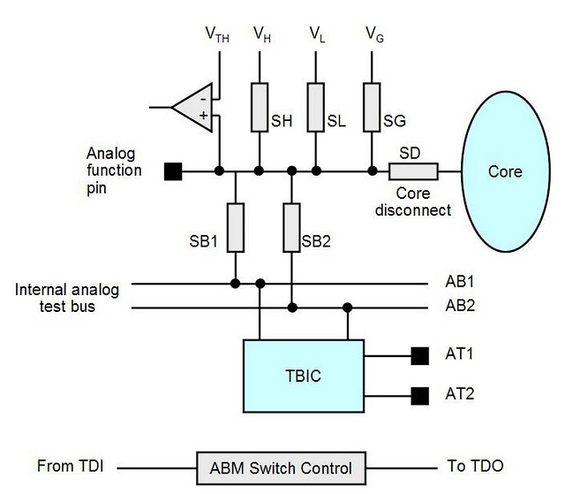 Figure 3. Analog Boundary Module Input Pin From Figure 3 we can again see the path from the analog tap AT1 through the TBIC and switching to the core of the IC. A switch SD is provided to isolate the core logic from the from the external analog function pin. This is useful to isolate the IC core circuitry from the external components that may be connected to either input or output pins. VH, VL and VG are also available to place a pin at high, low or constant voltage reference. Vth is available as a comparator for digital signals on the analog pin, so a pin can be monitored to be above or below a reference voltage. Example Application I have used analog boundary scan in my testing to test the leakage of capacitors connected to a pin. In Figure 3, if there were a capacitor connected to the analog function pin and I wanted to measure the leakage current, this is how to do it. The first step would be to put the system into EXTEST so that the core is isolated from the pin. Next, a power supply would be set up to apply a constant voltage through a DMM set to measure current and applied to AT1 or AT2. Finally, the cap is allowed to settle and the leakage current is measured from the DMM. Figure 4 shows how this is setup. 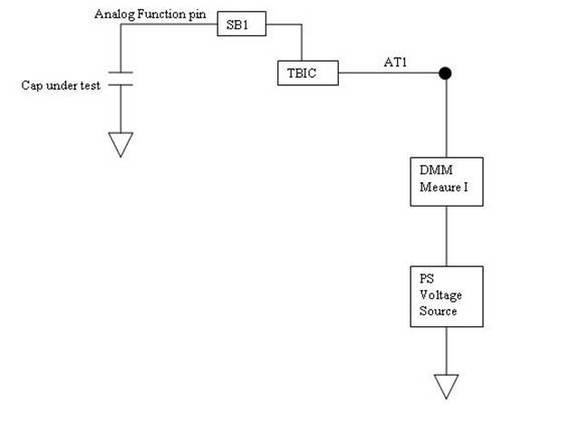 Figure 4. Setup for measuring capacitor leakage with analog boundary scan.
Summary Analog boundary scan falls under IEEE standard 1149.4 which is an extension of the digital boundary scan standard IEEE 1149.1. Analog boundary scan is extremely useful for making analog measurements when test access is limited or inaccessible. There are four main part of the system, the TBIC (Test Bus Interface Circuit), the analog test access port (ATAP) with pins AT1 and AT2, the internal test bus (AB1 and AB2) and the Analog boundary modules (ABM). The increase flexibility and test access is traded off with the increased costs to implement the system. |
Archives
December 2022
Categories
All

|
 RSS Feed
RSS Feed