|
This is a list of best practices I try to remember for myself when I do my work. I don’t always succeed in doing everything on the list, but this is what I strive to do. I realize some of these things might be part of a process you have to follow as a test engineer and if so that’s great. However, there are lots of times when just your own best practices are all you will have to go on. In those times having some discipline for yourself can save a lot of pain down the road. 1. Don't trust a measurement I've been tricked by measurements pleanty of times. When writing a new test with an unfamiliar instrument, there are a lot of things that can go wrong. Before you send a SCPI :meas and :fetch and call it good, there are many factors to consider. First, I try to understand how the instrument I am using works. It pays off to carefully read the manual. I don’t mean sit down and read the whole manual, but I’ll start with an example that is close to what I want to do and try to understand how it works. I might try removing some of the commands and see what happens. I often find I need to look up the individual commands and see what the description is. Here’s an example. I’ve written before about how I used a Keysight U2001A power sensor on a project a while ago and I remember how when I first looked at the examples they all have this frequency command in there. Like this:  You can see it just says FREQ 1000MHz and the comment doesn’t add much explanation. At first you might think that you are setting the instrument to measure the frequency of interest. Well, remember this is a power sensor and it inherently is a broadband measurement, and there is no frequency selectivity. If you dig into that command you’ll learn that this is a command to query previously stored frequency specific measurement offsets from memory on-board the instrument. Finally, when you think you have your measurement correct, find a second way to verify it like with a different instrument.
2. Write everything down This sounds like a pain and it’s easy to skip, but I find it’s more efficient in the long run to create a log of my work and debugging. I like to use OneNote, but I suppose anything would work. Start with a blank page or a page is dedicated to this task. Then, as you work through a problem take pictures of any important physical setups and write down settings or commands. Also record measurements and results that you get. This seems to help me from getting stuck in the short term and it's often useful to show others what I have tried to get something to work or just remember what I did. Another benefit is you can often reuse pictures and step-by-step descriptions to write really good documentation. 3. Get out and talk to people Not to put a label on engineers here, but it may not be in every engineer’s nature to go out and talk to people. In the course of a project, I try to get out of my cube and talk to other test engineers, talk to manufacturing, quality and design engineers. People generally like to help and they can often save you a ton of time. Weather it’s for a technical problem or a project management type problem, the more you can get involved the better. It also helps to learn who knows what, because you don’t have to know everything yourself, but you need to know who knows everything so you can ask them. Lots of communication! 4. Study the R&R I’m not crazy about using formal Gage R&R to evaluate test systems and electrical measurements, but it’s still worth doing to get an idea of how repeatable and reproducible your measurements are. I usually try to do a simple study where the test systems function as operators and test maybe 5 or 10 DUTs across three test systems. If you happen to have access to Minitab, it has a good tool called Gage Run Chart. It will give you a good visual evaluation of repeatability and reproducibility without all the percent of variation stuff that comes in the full R&R. All of the statistics produced by the full R&R can often just be misleading. Of course, in some industries there is a strict validation process for tests and test systems that will dictate exactly what to do. 5. Show my system to the users Put another way, work with the customer. I want to show my software and fixture operator interfaces to the people who are going to be using them as early as I can. It might not be fun, but it’s easier to get the feedback earlier when it’s still easy to change because they are going to make me change it one way or another. Lots of communication! 6. Try to break it Everyone has heard this when developing systems and software. Try to validate the system and perform all the tasks an operator would see. Make sure the test system can catch the defects it is intended it to. Try to think of ways the mechanical fixtures could be confusing or cause damage to the DUT. There is the Lean concept of Poke Yoke, that is making things mistake proof, I want to always keep that in mind. Think about how can a test system be abused or misused just to get the test to pass. 7. Be careful of stuff you don't control Oh man, I’ve been scorched by this before... Be careful if you have to get support from other parts of your company to do your testing. Especially if this support isn’t really what they would consider to be their job (even though it totally is). For example, if you are doing a test and you need the firmware department to build you a special firmware to perform your testing, this can be dangerous because it really only helps you and gives them extra work. I don’t mean this to sound like you can’t trust anyone type of a thing or everyone is against me type of thing, but it comes down to a lot of communication and early planning if support from other groups is required for success. Lots of communication! 8. Be patient and try to do it right the first time There is often project pressure and it can feel like people seem to forget that products need to be tested and manufactured. Try to resist the urge to, “just get something out there” and fix it later. It may seem like there is a lot of pressure to get done, but the pressure will get worse when the test isn’t working in manufacturing. Often the problem is just communicating with the team that the test isn’t ready and people will be willing to work with situation. This one can be really hard, but a test group the slaps everything together will end up in a huge hole after a few years of this. 9. Use high quality equipment I have this joke that every time I tell my manager how much something will cost they say “merciful heavens!” and then faint. Seriously though, I do think it always pays off to buy high quality equipment from real instrumentation companies. In general, avoid using USB instruments and devices in your test system. This is just my opinion, but I’ve had issues with problematic USB communications. At the very least use USB instruments from reputable vendors like Keysight and NI. Try to use a PXI chassis or even though it’s old, GPIB. Use an industrial computer with a consistent operating system. I’ve seen lots of times where test systems that are supposed to be the same are running on random PCs with different versions of Windows, 32-bit, 64-bit etc. I sometimes feel like I’m the only one who cares about this, but it’s important to get your computers from a real industrial computer supplier whose business it is to ensure a consistent setup. 10. Get stuff done I don’t know if this will make sense, but sometimes it’s easier to just wait for things to sort of figure themselves out, but resist this temptation, really try to get things moving and done. When I feel stuck, again the solution often seems to be lots of communication!
1 Comment
I have previously written about debugging, but that was more of a high-level abstract view. I think this is really important topic for test engineers and engineers in general. I am often disappointed in my own debugging skills, but also I have met very few people who are very good at it either. A tool I’ve been trying to use a lot for debugging lately is the Microsoft program OneNote. OneNote is great and I try to use it to write everything down. This post is a recent example of how I use OneNote to aid in my debugging. To set things up, I was having a problem with a test system I've been developing where measurements (in this case an RF power measurement taken with a USB power sensor) seemed to be working well in the short term and drifting in the long term. The first thing I did was to take a few repeated measurements and try to get a feel for this problem. It seems to me that the first part of debugging a problem is just sort-of playing around for a while to start to get a sense of it. The trouble with this is it’s easy to get stuck in this mode. This is where forcing myself to write things down in OneNote helps. It speeds up the transition from just playing around to drawing conclusions and start logically narrowing down the problem to the root-cause.  Figure 1. First segment of debugging session in OneNote. Looking at Figure 1, you can see that first thing I always do before I write something in OneNote is to right click and select the last option in the menu which is to insert your name, date and time. Next, I put some kind of title using the heading 1 style and write a few bullet points about what I’m doing. Using the heading 2 style, I break the notes up further into separate little experiments. I don’t really have anything that defines an experiment, it just sort-of breaks up the notes into how the thought process goes. I then start taking some measurements and recording the results. I’m not that careful about recording all details of the experiment, like the equipment I used and while that would be a good addition, I just use the notes to aid in my thinking through the problem. As you can see, the measurements start at -28 dBm and rise to -25.2 dBm. I would expect them to stay within about 0.1 dBm. A couple more notes, when I refer to “box” that is basically the test system and “golden unit 5349” is a known good and characterized DUT that I can trust. At the end you can see I wrote a little conclusion for myself that basically just says, this isn’t doing what I would expect I have to keep debugging. What’s important about writing a conclusion here is that it forces me to stop and think of how to isolate what is going on. I could easily continue making this measurement all day and not learn anything more. This is what I was talking earlier, about getting a feel for the problem. You have to start somewhere but also focus on how to quickly move past this stage.  Figure 2. Experiment 2 attempts to isolate the problem to a specific part of the test system. Continuing on, Figure 2 shows the different configurations I went through to try to recreate the variation. You can see I tried cycling the DUT power (the DUT is battery powered and the battery voltage can have an effect on the output power) and different batteries. If you look carefully at some of the text you'll notice it was not written at the same time the measurements were taken. I went back at a later time to add this text as I learned more about how to properly setup and measure with the spectrum analyzer. As you can see, the measurements with the spectrum analyzer were pretty consistent.  Figure 3. Spectrum analyzer measurements after improving how the measurements were taken. In Figure 3 I’m still making the same measurement with the spectrum analyzer, but now I’ve setup a trigger so those measurements should be more repeatable and comparable.  Figure 4. Continuation of Experiment 3, drawing conclusions about this measurement. Figure 4 shows more of the section labeled “Experiment 3.” I’ve now switched back to the power sensor and am spacing out the measurements over a longer time and recording when they were taken. At this point, I was thinking that the length of time the system sits idle had some effect on the measurement and usually if a measurement changes over time it’s due to some sort of environmental factor. I just know this from experience and that’s why I’ve also started noting the general temperature of the power sensor. I know these power sensors can get quite warm. Towards the end, I added measurements from a second test system to look for variation due to cold versus warmed-up power sensors.  Figure 5. Last portion of Experiment 3 and the OneNote debugging session of the inconsistent power measurement. Figure 5 is the last of the measurements, you can see that I continue to track the time of each measurement and there are two big surprises related to the measurement. The first surprise is the first line, the measurement is now 2.57 dBm lower on the same setup than it was just an hour ago. The second big surprise is the power drops a ridiculous 17.24 dBm after the system is left powered overnight.
The big breakthrough was when the power sensor was consistently measuring down at -40 and the spectrum analyzer was still measuring up at -24. This told me that the power sensor was the problem and it was what was causing the measurement variation. This made me feel pretty stupid, as I had been working with this power sensor for a while and its measurements were apparently useless (but I was making progress). At this point I had identified a problem and need to find a way to fix it. I did know that power sensors need to be zeroed before taking measurements, but I had thought I had read in the instrument manual that this was done automatically when the sensor was powered up or the temperature changed by 5 degrees. I decide I could verify the zeroing had been done by explicitly adding the commands to zero it before each measurement. Well as you can see in Figure 5, the measurement snapped right back into line with the spectrum analyzer once the zeroing had been done. I then wrote my final conclusion that this was a big source of the variation in question and the power sensor should be zeroed before every measurement. My conclusion was temperature change was the source of variation and it was not being accounted for. Summary In this article I went through my process for debugging a real problem I had and showed how writing aided in that debugging. I’m not so much trying to show what a genius debugger I am, but that my debugging gets way better if I force myself to write things down as I go. I think Microsoft OneNote is a great tool for this purpose. Guard-banding is the concept of tightening test limits by the amount of your measurement accuracy in the measurement system in order to prevent bad DUTs from being mistakenly passed. For example, let’s say you are taking a measurement with a specification limit of 5 volts and the measurement system being used to measure a DUT has a measurement accuracy of 1 volt. To make sure that a DUT with a true value greater than 5 volts does not pass, the limit should be guard-banded by the 1 volt measurement accuracy and set at 4 volts. Here is how this works. You have a DUT with a true value of 5 volts that could be measured anywhere from 4 to 6 volts due to measurement accuracy of 1 volt. See Figure 1. 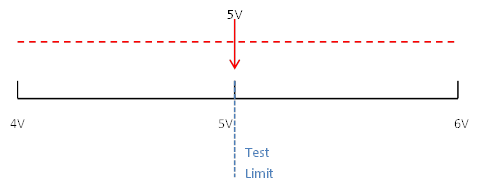
Figure 1. Range of 5V true value with 1 V measurement error.
If the test limit is set at 5 volts according to the specification, then half of the time this DUT will pass and half of the time this DUT will fail. This is an example of a DUT we would want to pass, but might false fail. Now let’s say that there was a DUT with a true value of 5.5 volts. We would never want this DUT to pass but it would pass 25% of the time. See Figure 2. 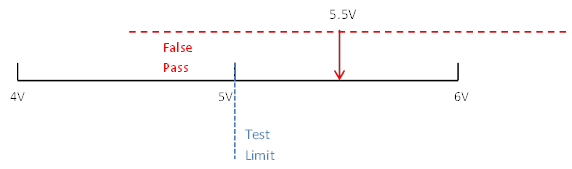
Figure 2. Range of a 5.5V true value with a risk of a false pass.
To avoid the potential of a false pass a guard-band can be applied to create a test limit of 4 volts. Now, with the limit at 4 volts the DUT with a true value of 5.5 volts from Figure 2 can never pass. See Figure 3. 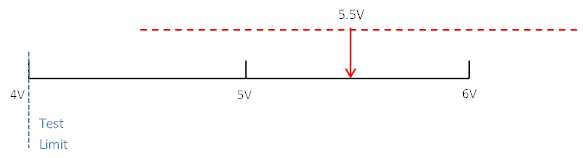
Figure 3. 1 volt guard-band applied to a 5 volt true value.
It’s pretty easy to see that applying a guard-band will potentially fail more good parts. This highlights the importance of knowing where your measurement population is compared to your test limit and having an accurate measurement system. This brings up the concept of CPK which is a measurement to determine if your measurement population is too close to your limit.
When talking about debugging people might think of debugging code, and while that is part of it, I’m referring to the larger problem of solving test issues no matter where they are found. Perhaps trouble-shooting is the correct term, but either way every test engineer has to do it and it can be a difficult skill to learn and perform effectively. Debugging mostly comes down to being able to think logically, but it’s not just something you are born with you have to learn (and usually the hard way) by doing it over and over until it becomes natural. I don’t think debugging is something that normal people (normal people are non-engineers) are very good at and a lot of engineers are not even all that good at it. It’s not really their fault; they just haven’t had enough practice. Despite all this, there are some tips to keep in mind while debugging, these are the type of tips that are easy to know but not always easy to follow. There are two main situations where a test engineer has to debug something. - Debugging problems that occur during test hardware and software development - Debugging unexpected problems that occur during manufacturing after you think you are done. These are more serious problems and often much more difficult to solve. Below these two categories there is another division of either a constant or intermittent problem. From there, most of the debugging techniques used are the same. The constant type is much easier to solve than the intermittent type. Intermittent test problem I’ll start with the more difficult type of debugging task, trying to find an intermittent test problem. These problems are usually revealed due to the increased volume when a test is initially being run in manufacturing. When faced with an intermittent failure like this, the first thing I usually do is look at the test report and try to see if it’s telling me anything. Is the problem that the test fails a limit or is there some software error being generated? If it is a limit failure that might just be a bad part and the part might need to be retested or otherwise analyzed. If it’s a software error, I’ll think about the error in the context it occurred and see if there is some reason for it. Like is an instrument giving an error because it’s trying to measure out of range. So, if you eliminate these obvious things and the DUT seems good, you have a true intermittent failure. It may fail every other time or 1 in 1000 times, either way it’s time to get in the lab and debug the problem. Recreate the problem Before you can fix the problem you have to understand it and to do that you have to be able to recreate it. It is sort-of Murphy’s law that these things be difficult to recreate, but you can’t really be sure the problem is fixed until you can cause it to happen and then apply your fix to prove the problem is gone. It’s quite possible that recreating the problem will be the bulk of the work because you will end up understanding what it going on if you can recreate it. When trying to recreate a problem you often fall into the following pattern. - Looping the test - Look for patterns in the looping data - Change something - Loop again Looping the test means to setup the test to run over and over on the same DUT and test system setup until it fails. You probably won’t learn anything just by looping until the failure happens again. You take measures to gather more information in the event of a failure. For example, maybe you suspect a noise signal causing a problem so you set up a scope to trigger on a spike and see if is the scope shows anything upon failure. Or, you modify the code to stop on a breakpoint when the failure occurs and hopefully the DUT is left in a state where the problem can be repeated. These are the ways you gather clues to see what was different about the test run on the times it failed. When you change something you are hopefully affecting the failure rate, with the goal of making it fail every time. This might seem strange, because you might think that change the test so that it fails is just breaking it. What you are doing it trying to exacerbate a situation to make the intermittent failure occur all the time or at least more often. If you can make it fail more often you know you are maybe on the right track. An example might be that in a test you provide power to a DUT and program a delay into the code to allow the DUT time to reach steady state. Maybe this delay is just on the borderline, so that when you were developing the code you never saw the problem but really 1 out of 100 times it is a problem. So, you can make the problem worse by shortening the delay and seeing if the failure occurs more often in the looping. Change one thing at a time This is important, when you change something, just change one thing at a time. This is a hard rule to follow, especially if you have to loop in-between because you have to be so patient. Also, if you change something and it doesn’t have an effect, change it back before you change something else and try again. If you don’t do this you can get lost very fast, because now you don’t know if the latest change or the combination of the latest change and some previous change is making the difference. Take small steps In addition to only changing one thing at a time, change things in small steps if possible. Let’s say that you are looking for a glitch on a signal by monitoring it with an oscilloscope. Say you are changing some parameter of a test like a delay or a voltage. You might think to try a low voltage and a high voltage and this does not appear to have an effect, but really you have missed some behavior that is a clue by jumping the voltage too fast. Take small steps. Ask for ideas If you have a collogue who will listen, it helps to run through the problem and all the things you have tried with them for some ideas. They may know something about the system you don’t or might have some ideas that didn’t occur to you. However, you have to know who you are asking, that they have the skills to help and that they will be willing to help without trying to take over. Think about the assumptions Think about the assumptions you are making. Do you really understand everything you think you do? Are you assuming that the problem is not related to a certain piece without having proved it? Write everything down Keep track of what you have tried, it sounds silly but you can go crazy pretty fast on a tough problem and just start spinning your wheels. Look back at what you have done and this will help you to think logically and see patterns. Nothing works It is quite possible that you will not be able to make the problem worse and make the problem repeatable. All the debugging techniques like only changing one thing at a time and taking small steps still apply. However, you are stuck in the change, loop, wait cycle which is much slower. Really if you are able to recreate the problem, you are most likely 90 percent of the way to solving it. Isolate the problem Once you can reliably recreate a problem or you have a repeatable problem to begin with, you can start using a logical process of elimination. Is the problem in hardware or software? Is it the DUT or the test system? You have to start crossing things off the list and narrow it down. It is much easier to debug if you have multiple instances of all your hardware, that way you can swap them in and out to hopefully isolate a problem. Here is an example of the process of elimination. A test system is a complex system. A problem can be in the DUT, the tester the ITA, the fixture or the software. It’s just a flow chart. See Figure 1. 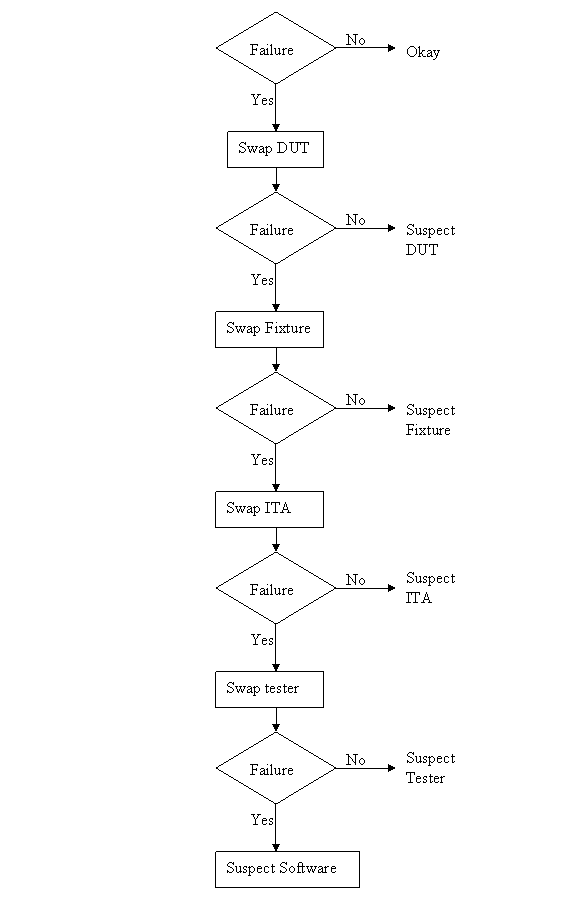 Figure 1. Isolating a problem among test system components. Recreate the experiment Once you think you have recreated the failure or found a pattern where if you make a certain change it has a certain effect, then try it all again. That is, turn everything off or take apart the setup and try to recreate the whole thing. Make sure your experiment is repeatable. I’ve had it happen many times where I thought I had a pattern only to have it go away when I start again. This is the type of thing that happens if you make more than one change at once and forget about the changes you have made. Prove it another way Try to prove everything two ways. So, when you think you have a pattern figured out try to think of another way to prove it that is independent. Maybe you found some noise on a digitized waveform, try to see the noise on an oscilloscope to make sure it’s real. You will ultimately have to convince someone you have found and solved the problem, this second proof will strengthen you case. Example I recently had an opportunity to do a simple debugging task at home. Granted, this is very simple, but it somewhat illustrates the debugging process. I have an old DirecTV DVR receiver that was often having the signal on Input 2 break-up. (a DVR has two coax inputs so you can record two shows at once) Figure 2 illustrates the setup.  Figure 2. Satellite TV with DVR setup
The first thing to do is to make sure you know what problem you are trying to solve. In this case, the problem is that picture on Input 2 is goes out and breaks up intermittently. Next, I had to think of all the things that could be wrong and start eliminating them. So, the Satellite dish on the roof might have a problem, Cable 2 might be bad. The input or tuner on the DVR might be bad. I’m hoping that the result is the DVR is bad because it’s over five years old and ready to replace anyway. This is my main suspicion because as crazy as it may sound I’m sure five years is a remarkable amount of time for a piece of consumer electronics to last. Also, it seems logical as this is by far the most complex piece of the system. Having thought it through this far, the objective is now to prove that if I replace the receiver that it will work and that will fix the problem. The first thing I tried was to check the signal strengths of the two inputs using the DVRs menu. It said 95% on input 1 and 87% on input 2. Hmm… that doesn’t tell me that much. While this doesn’t rule out the DVR it probably means the dish and cables are fine. It is interesting that input 2 is a little bit lower, that might be just a random result. At this point I had a much better idea, if I switch the two cables going to the DVR and the problem stays on input 2, then the DVR is the problem. If I switch them and the problem follows to input 1 then the cables or dish are the problem. Well, after switching them the picture on input 2 was still breaking up confirming my suspicion of the DVR input 2 being bad. I have since replaced that DVR with a new one and it is working great. Of course I never really got to the root cause of the problem with the DVR, but in this case I don’t really care and it may not be possible to find that without more information about the DVR itself anyway. Summary Debugging is a difficult task because this is how you tackle the most difficult problems. There are some concrete techniques to keep in mind when debugging. The keys to debugging are being patient and methodical. Write down what you have tried and try to think as logically as you can. It’s interesting that often times you will amass all these clues that seem to mean things or are patterns and some of them seem to contradict each other. When you finally figure out the root cause and really understand what’s going on, everything makes sense. You find yourself seeing the light and all the pieces fit. That’s a good feeling. Most measurement comes down to measuring voltage or current. The simplest way to measure voltage would be with a DMM set to DC Voltage. A lot of ATE type instruments still just measure voltage but add a lot of higher level functions and increased capabilities. I’m going to look at some simple measurement issues and then some more advanced instruments and what they can do. Measurement Basics Voltage and Current Measurements are the basic measurements that are the basis of what the various measurement instruments do. Voltage is measured in parallel across two points and current is measured in series, in the current path. A resistive measurement is made by measuring both the voltage and current and calculating the resistance using ohms law. A useful improvement to measuring resistance is to use a 4-wire or Kelvin measurement. Figure 1 shows how a 4-wire measurement is made. 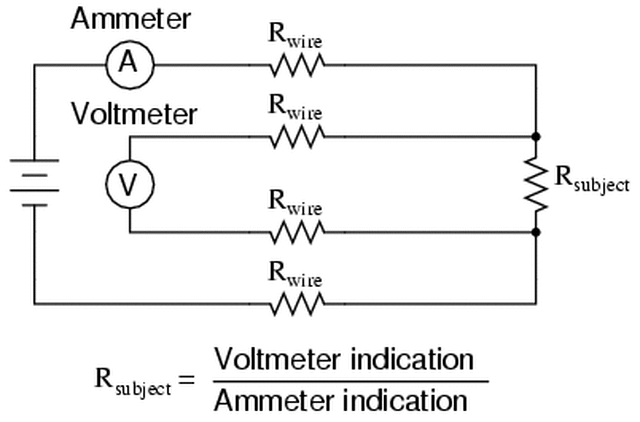 Figure 1. A 4-Wire or Kelvin resistance measurement. In Figure 1 a separate wire is used to connect the ammeter and the voltmeter to the resistance you intend to measure. The advantage here is that the forced current causes voltage drop on its’ wires but not on the voltmeters’ wires. So, the voltmeter sees very little current and the measured resistance is more accurate. Instrument Accuracy It’s important to understand how to calculate accuracy for the instrument you are using. It happens all the time that a measurement seems like it is not working, only to determine that the problem is the accuracy of the select measurement range. Figure 2 shows the DC voltage accuracy specification for the National Instruments 4071 PXI DMM. 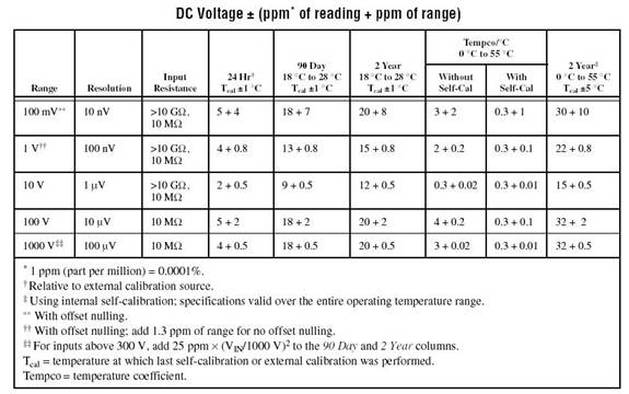 Figure 2. DC voltage accuracy specification for the National Instruments 4071 PXI DMM. Figure 2 shows that accuracy is calculated as parts per million of reading plus parts per million of range. The figure shows many different columns that are related to the calibration and temperature. For example, within 24 hours of calibration in the 100 mV range the accuracy is 5 + 4. If you are trying to read 50 mV, the accuracy will be calculated as follows. 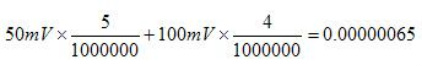 Or 650 nV. To make it a little simpler you could just calculate the worst case accuracy for the range you are in and know you will always have better accuracy than that. To do that, add the measurement and range together and take the full range voltage, like this. 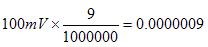 Or 900 nV. Accuracy isn’t always in PPM, sometimes it’s given as a percentage, which I think is a little more intuitive, but it’s still the same idea. While the instrument itself has accuracy as just discussed, there are many other factors that can affect measurement accuracy. These include: input loading, leakage resistance and current, shielding and guarding. Here is another example of calculating accuracy, in this case for resistance. Figure 3 shows a resistor where the voltages are known on either side of the resistor. 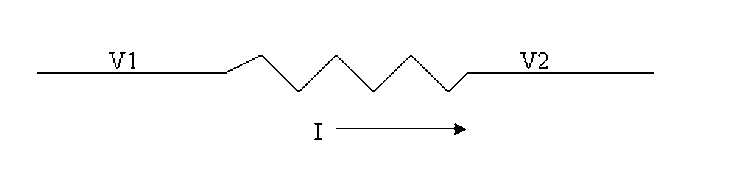 Figure 3. Resistor to be measured  Error The error is how much a measurement differs from the true value. Usually, this is a ratio where the maximum error can be calculated based on the worst case observed or calculated measurements. For example, if you take the 50mV with 650nV of measurement error from above, as a percent the worst case is:  Resolution
The table in Figure 2 also has column for resolution. Resolution is the smallest portion of input signal that the instrument can display. For a 5½ digit display, there can be 200,000 counts (0 to 199,999). This makes the resolution of the display 1/200,000 = 0.0005%. Sensitivity This is kind of like the resolution, it is the smallest change in the signal that can be detected. The instrument has to detect and display a change in a signal, which is calculated based on the resolution and current measurement range. If the range is 200mV and the counts is 200,000, then 0.2/200,000 = 1 uV sensitivity. There are also calculations for sensitivity based on the number of bits the instrument uses (this is bits on the ADC or DAC), if you had 10 bits the sensitivity is your input range divided into 2^10 parts. Depending on where you look the definition given here for sensitivity may be the definition given for resolution. It’s kind of up to the different instrument manufactures as to how it’s defined. Range The range is pretty obvious, you want to make sure you are not trying to measure a value that is larger than the selected range. However, just selecting the largest range possible all the time will hurt the accuracy of the measurement. I would say you want to measure in a range where the value you are attempting to measure are less than 90% of the range. If you are above 90% consider if you are going to see variation that will be out of range. Precision The term “precision” is used a lot, but this really a more informal term that should not be substituted for accuracy. It is defined more in terms of measurement repeatability and reproducibility. It’s easy to find an explanation of accuracy vs. precision that usually involves a dart board. Instrument Types There are many different types of instruments, I’m going to try and cover the most general purpose ones that I have worked with. DAQ A DAQ is kind of its own class of instrument that covers multiple functions all in one instrument. If you look at the websites for National Instruments or Keithley, they list a DAQ in its own section even though it duplicated the function of many other instruments. A DAQ usually contains a counter/timer, digital I/O lines, analog I/O for single values, waveform output and digitizing. This really covers a lot and you can do a lot with a DAQ. When higher performance is required, that is when you need to go to more specialized instruments, like ARBs or High Speed Digitizers. DMM/LCR A DMM (digital multimeter) is usually required over a DAQ when increase accuracy for measurements is required. The trade off with a DMM is usually speed, in order to achieve higher accuracies the DMM internally averages measurements over a longer time. Many DMMs also have the ability to digitize waveforms, only at slower speeds relative to other digitizing options. In addition to voltage, current and resistance many DMMs include LCR capabilities, measuring capacitance and inductance. A DMM is often specified in terms of digits. The NI 4071 from Figure 2 is a 7½ digit DMM. Where we have 01.234567 if this was the number you were reading from the DMM, the 1 through 7 is the 7 digits and the 0 is the ½. It is only ½ because this digit can only be a 0 or a 1. If you look at the ranges in Figure 2 the ½ digit really only becomes a 1 when the range is maxed out. Programmable Power Supply, SMU A programmable power supply is just what it sounds like. A power supply that can be controlled through software. An SMU (Source Measure Unit) is a programmable supply that also has measurement capability. An SMU can typically be configured to force either voltage and measure current or force current and measure voltage (FVMI, FIMV for short). The SMU works where you set the voltage you want to output and set the maximum current limit. Then, the instrument will vary the current in order to hold the voltage constant and generate some type of alarm is the current limit is reached. Another nice feature of SMUs and programmable supplies is the ability to sweep outputs through a list of settings. ARB, Function Generator An ARB or arbitrary waveform generator is a little different from a function generator in that the output can be programmed to a custom waveform. A function generator will typically only generate preset waveforms like sine or square waves. Again, having a DAQ might make these instruments unnecessary, it just depends on the specifications of each. Some features that may be better than a DAQ are: higher speed, higher accuracy, more triggering, and ARB options, improved noise performance and filtering. Counter Timer A counter timer is an instrument for counting pulses and measuring frequencies. Some applications I’ve seen include counting the number of times a signal crosses a set threshold in a given time. Generating a tightly controlled timing signal. That is, a signal is output at logic high from the counter timer and that signal is used as an acquisition time for a measurement. Oscilloscope, High Speed Digitizer High speed digitizers or the similar but more flexible oscilloscope are need for measuring high speed signals that are too fast for other options like DMMs or DAQs. Where these instruments are really useful is for what’s called visualization which means, seeing what’s going on. When something is not working, it’s often important to have a high speed oscilloscope in order to catch the noise or whatever glitch might be causing the trouble. Summary A few basic concepts are important to know when making electrical measurements, like how to determine the accuracy and knowing the effect of resolution and range on measurements. A few points on several different types of instruments were covered. There is certainly a lot more to know about any of these instruments, but I feel these are the kind of basics that I keep in my head about any of these to have a simple knowledge of what they do. Test engineering is a sub-discipline of electrical engineering that isn’t really well defined but people who are test engineers tend to know it when they see it. I have been working as a test engineer for the last seven years.
I work for a large medical device maker where I focus on manufacturing electrical test at the circuit board level. When I think of test engineering it comes down to instrumentation, measurements and automated test systems. I’d like to expand my view of what is, sort-of is and isn’t test engineering in a way that other test engineers can agree with. What test engineering is not Software testing Software testing is not what test engineers do because test engineers tend to have a background in electrical engineering or as an electrical technician. Software testing is something that computer scientists do (or probably don’t want to do). Software development / Software engineering Test engineers do a lot of programming but they are not software developers. The code that test engineers write is really more like scripts to control instruments and take measurements. Design verification testing I don’t really think of design verification as what test engineers mainly do. Test engineers focus on testing products during the manufacturing process. Testing that the design does what it’s supposed to do is what the design engineer does. What test engineering (sort-of) is Quality assurance At a large company there will be quality engineers or a whole QA department. They do things like analyze products for failure modes and track product failure trends. They might be the people who ask the test engineers to implement new test methods or test coverage to detect a newly discovered failure mode. They will commonly do more data and statistical analysis than test engineers. They also will focus on predicted reliability of a product and analysis of returned field product. Manufacturing engineering This job is more often overlapped with the job of the test engineer but again at a large company they are usually separate positions. The manufacturing engineer focuses on taking the tests software and systems developed by the test engineers and deploying them to the manufacturing floor. They will focus on the yield of the product being tested and making sure that the test systems are working and under control. Under control is a statistical method of looking at the measurements a test system is making to be sure it’s still measuring correctly. If one device under test fails it’s probably a bad part, if nine out of the last ten fail, something has gone wrong with the test system. What test engineering is TE is all about measurements and automated test systems to make measurements on products on the manufacturing floor. Depending on the test strategy being implemented, electronics may be tested in all or some stages while being built. Testing may take place on the individual components, integrated circuits, PCBs and finished products. Component testing Components may be tested by a vendor, sampled and tested or 100 percent tested before they are used in a product. Large companies often have people other than test engineers working with component suppliers to determine how their components are tested and manage that relationship. Integrated circuit testing Integrated circuit testing is a specialty of test engineering that is the most complex and costly of the testing. This is often performed by the chipmakers themselves or outsourced due to the high cost of buying “big iron” testers. A company like Teradyne focuses on building extremely expensive and large test systems for integrated circuits. PCB testing Testing a PCB can be a very flexible place to perform testing. With a PCB there is still access to the circuits through test pads (this isn’t always true with some products being so small, there is no real-estate to spare for test access or boards are multisided) and also access through techniques like BIST and Boundary Scan. Also, it’s still cheaper to find a problem with a PCB than find it with a finished product that won’t turn on. Since it is so flexible, how a PCB is tested is variable. In my industry there is often a bed-of-nails type DUT interface along side a test system. But, the list of variables include, cost, volume, PCB complexity, application and level of regulation. This all gets to test strategy, which I plan to write about in the future. Finish Product (functional) testing Functional testing is a somewhat broad term. It could be interpreted to mean that when you power up and operate an electronic product it simply works or it can mean testing some higher-level functionality at a lower level. For example, while still at the PCB level a product could have sub-sections of the system functionally tested for some higher level measurement like the bandwidth of an amplifier. Another way to think of it is once you lose any access to the system, like probing test pads, and the product is complete then functional testing is taking place. Inspection It’s worth mentioning that inspection is slightly different than testing. Testing is where a product is built and then it is measured to determine if it is has defects or functions correctly. When a product is tested and it doesn’t work, there is no going back, you either scrap it or repair it. With inspection a product is observed to check for defects so it can be caught earlier. For example, you could test a completed circuit board or you could inspect an unpopulated PCB to look for a broken trace so all the time and expense of populating that PCB with components can be saved. Reliability testing I mentioned that reliability activities are not always the job of the test engineer. That might seem a bit strange, but really there is a difference between testing a product to see if it is working right now when it is shipped, versus attempting to perform tests to try to predict if a product will continue to work for its expected lifespan. These types of activities would be considered reliability testing. One such type of test would be a burn-in test, where the product is tested in a high temperature environment in an attempt to remove weak products. Incidentally, just testing something at high temperature doesn’t reveal many latent problems. What is much more effective is to test in a temperature cycle, forcing the product to experience the expansion and contraction stress. Humidity is another important environmental variable in determining reliability. Summary There are a lot of issues to consider and steps in the process of testing electronic products. I have gone over it really fast in an effort to establish the basics without going into a lot of detail. I’ll dive into many of these topics in more detail in the future and hopefully I won’t miss too many important considerations in test engineering. As a test engineer before you can start building a test system or writing test code you have to decide on a test strategy. You have some sort of electronic product that needs to be tested before it can be sent to the field (sold). The question is, what problems could the product have, where and how are they going to be detected? Most companies already have some idea of what their strategy to test and overall product quality is, but these decisions have to be made or were made at some point.
Three Ways to Fail There are three ways an electronic device can fail 1. Poor quality raw materials 2. Design is incorrect 3. Process variation That’s it, three ways. So, what does each of these entail? 1. Poor quality raw materials An example of this would be defective components or bad PCBs. 2. Design is incorrect This is just what it sounds like, the product as designed does not meet its specifications. These errors should not have to be checked for on every instance of a product that is built in manufacturing. These problems should be caught early in the design validation and verification. However, design problems can show up in the manufacturing test, particularly when high volume manufacturing measurement data is analyzed. Some design problems - Does not meet analog specifications - Digital logic error - Functional failures 3. Process variation This type of failure is basically manufacturing errors. Here is a list of a few manufacturing errors - Shorts - Opens - Missing component - Wrong component - Backwards component - Bent Leads - Functional Failures Failure Mode Effects Analysis There are certainly a lot of failure modes that can happen to electronics in general but how do you know what failure modes to test for in a particular product? One way is to perform an FMEA. An FMEA is a formal method for determining what could go wrong so you can design a test strategy to check for all these failure modes. It is easy to find an FMEA worksheet on the internet to see how it works. The idea is to think of all the possible failures for each function or sub-system (or however you break it down) and then rate those failures by how serious their consequences are, how frequently they occur, and how easily they are detected. Here are some typical fields in the FMEA table - Function - Failure Mode - Effects - Severity Rating – this could be 0 to 10 or 0 to 3 or whatever works. - Causes - Occurrence Rating - Current Controls – what should be preventing this failure from happening in the first place - Detection Rating - Risk Priority Number (RPN) – This is a method to make an overall ranking of the items, this is the three rankings multiplied together. RPN = S * O * D. Test Strategy Complexity In reality, a test strategy comes down to the type of product you are testing and how much money you have to spend to test it. If you are testing a toy fire truck with an electronic siren I’m sure all the testing that takes place is pressing the button to see if the siren goes off on the completed toy, if that. Of course in a mission critical situation the test strategy could be very complex and expensive and would require a lot of work to design. Here are some additional factors to consider when developing the strategy. Cost – How much budget do you really have to work with? How much testing can you do with that money and where are the most important places to apply it? Volume – What volume of this product is being built? Product Complexity – How complex is this product being tested? Will it require a lot or little testing? Will the testing have to be broken up into multiple levels and tactics? Level of reliability needed – How reliable does the product you are testing really need to be? Ideally, it would be 100% for anything, but it’s really more about what testing is cost effective to perform. Environment where the product is used – will you have to duplicate any extreme conditions to verify that the product will work under those conditions? How to handle ASICs and components? – Will you assume that all ASIC and components are good before they are used on a board? Do you need to sample or fully test these components in-house? Outsource – will any of the testing be outsourced to another company? Is there a way to outsource part of the testing or building equipment that makes sense? Environment Stress Screening (ESS) or Reliability testing – Will you have to attempt to predict the reliability of the product or just verify that it is working correctly as it is built? Test Levels – Is there a way to divide up all the necessary testing into different levels that will make the testing simpler or cheaper? Some test levels include: - Incoming inspection, vendor test - Prescreen (auto shorts, opens, manual inspection) - In-circuit test of manufacturing defects analyzer - Board level burn in or ESS - Functional or performance - Hot mockup - System burn-in - Field test Test Tactics – A test strategy is the why and the test tactic is how. What methods will be used to best implement your test strategy? Some test tactics include, - In circuit test - Functional - Emulation - Inspection - Hot mock up - Design for test - Boundary scan - ESS Two Test Strategies There are two general strategies that can be taken when building a product. 1. Build it correctly the first time 2. Build it, test it and repair the failures 1. Build it correctly the first time This may seem like what you would obviously try to do no matter what, but it goes beyond just trying to do a good job. This is really the idea of putting inspection and process monitoring into your manufacturing process. As an example, components may be screed before they go onto a circuit board, then the circuit board undergoes some type of inspection, maybe an IR inspection and process monitors are put on this inspection. Finally, the final product is built with some final functional testing. It may be more elaborate than that but the idea is to end up with nearly 100% yield at the final testing. There is no need for scrap, debug and repair. This is really what Lean manufacturing and Six Sigma type concepts are all about. Judging from the volume of information about these topic on the internet, this strategy is very popular right now. 2. Build it, test is and repair the failures Here the products would be built without worrying too much about inspection or process monitoring then the products would undergo electrical testing. Anything that fails the testing is then debugged and repaired. The advantage here is that you saved a lot of time, cost and effort building the products. So, if the yield is okay and this method is appropriate for the product being tested, it should be fine. The disadvantages are that you have either lots of scrap or lots of products to debug and repair. The testing that was preformed should be an aid, but it still may be pretty difficult to debug and repair the problems. Summary Few engineers really get the chance to develop a test strategy from scratch because it can be tough to change the momentum of a company at such a fundamental level. However, if an engineer knows all the issues that go into a test strategy they can pick spots that and argue a case for changing them. Test strategy can be very simple or very complex, it’s all based on the product you are testing and the goals of your company. |
Archives
December 2022
Categories
All

|
 RSS Feed
RSS Feed